Các thành phần và nguyên tắc của tuabin khí [Giải thích đầy đủ]
346
Các thành phần và nguyên tắc của tuabin khí [Giải thích đầy đủ]
Các thành phần và nguyên lý tuabin khí
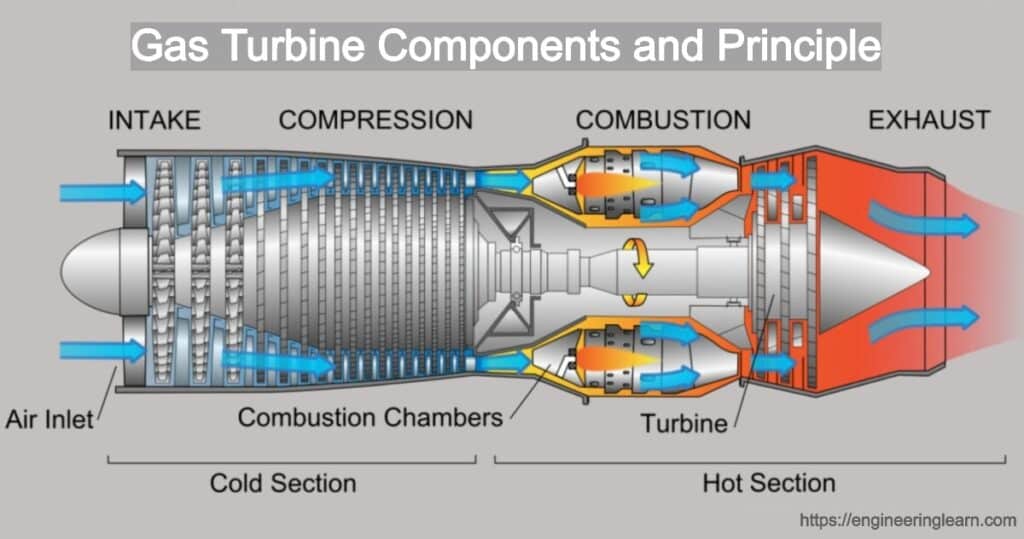
Linh kiện tuabin khí và yple Princ: – Tuabin khí là một loại động cơ đốt trong có chất lỏng làm việc là chính không khí. Động cơ được sử dụng để trích xuất năng lượng hóa học từ nhiên liệu và cũng được sử dụng để chuyển đổi năng lượng hóa học thành năng lượng cơ học bằng cách sử dụng năng lượng khí làm chất lỏng làm việc để dẫn động động cơ và cánh quạt, điều này, đến lượt nó, đẩy máy bay.
Thành phần tuabin khí
1. Đầu vào
Không khí nên được giữ cho lưu thông không bị hạn chế từ ống dẫn và ống dẫn đầu vào cũng phải gọn gàng và sạch sẽ để giữ cho động cơ khỏe mạnh. Bạn nên cung cấp luồng không khí sạch và không bị xáo trộn ở đầu vào mà khi được cung cấp cho động cơ sẽ tăng hiệu quả và bảo vệ động cơ khỏi bị xói mòn, ăn mòn hoặc bất kỳ hư hỏng nào.
Người ta cũng đề nghị rằng các bộ phận nên được lắp đặt trong ống dẫn khí đầu vào của động cơ và ống dẫn đầu vào để đảm bảo rằng tổn thất luồng không khí là tối thiểu đối với tất cả các điều kiện của luồng không khí.
2. Máy nén khí
Máy nén là máy chịu trách nhiệm cung cấp cho tuabin lượng không khí cần thiết cần thiết để làm cho nó hoạt động một cách hiệu quả. Thêm vào đó, cần phải cung cấp không khí ở áp suất tĩnh rất cao. Tỷ lệ áp suất thường được biết đến ở máy nén phía sau so với áp suất ở máy nén phía trước là 9: 5.
3. Bộ khuếch tán
Không khí thoát ra qua các van dẫn hướng của máy nén, nơi các thành phần của luồng không khí được chuyển đổi thành dòng chảy thẳng. Sau đó, không khí đi vào phần khuếch tán, là một ống dẫn phân kỳ. Chức năng cơ bản của bộ khuếch tán là khí động học.
4. Bộ đốt
Khi không khí đi qua bộ khuếch tán, nó đi vào phần đốt cháy được gọi là bộ đốt. Phần đốt có nhiệm vụ kiểm soát việc đốt cháy nhiên liệu và không khí. Nhiệt được giải phóng phải theo cách mà không khí được mở rộng và tăng tốc để cung cấp một dòng chảy trơn tru và ổn định cho một loại khí được làm nóng đồng đều ở mọi điều kiện hoạt động. Bắt buộc phải hoàn thành nhiệm vụ với tổn thất áp suất tối thiểu và giải phóng nhiệt tối đa.
5. Tuabin
Một động cơ tuabin có một tuabin bốn giai đoạn được sử dụng để chuyển đổi năng lượng khí của nhiên liệu không khí thành năng lượng cơ học để di chuyển máy nén với sự trợ giúp của bánh răng giảm tốc hoặc cánh quạt. Tuabin có chức năng trong đó năng lượng khí được chuyển đổi thành năng lượng cơ học bằng cách mở rộng các khí nóng và áp suất cao thành nhiệt độ và áp suất thấp hơn.
6. Khí thải
Khi khí đi qua tuabin, nó sẽ được thải qua ống xả. Hầu hết năng lượng khí được chuyển đổi thành năng lượng cơ học nhờ sự trợ giúp của tuabin, một lượng năng lượng đủ còn lại trong khí thải. Khí còn lại này được tăng tốc qua ống dẫn hội tụ của ống xả để làm cho nó hữu ích hơn khi máy bay lái.
Nguyên lý làm việc của tuabin khí
Nguyên tắc cơ bản mà tuabin khí hoạt động giống hệt với tất cả các động cơ được sử dụng để trích xuất năng lượng từ nhiên liệu hóa học. 4 bước phổ biến nhất được biết đến cho bất kỳ động cơ đốt trong nào như sau:
Cửa hút khí.
Nén khí.
Quá trình đốt cháy, nơi nhiên liệu được phun và chế tạo để chuyển đổi thành năng lượng dự trữ.
Mở rộng và tuyệt chủng, nơi năng lượng chuyển đổi được đưa vào sử dụng.
Trong trường hợp động cơ piston giống như động cơ được sử dụng trong ô tô hoặc động cơ máy bay, các bước liên quan là nạp, nén, đốt cháy và xả trong đầu xi lanh nhưng tại các thời điểm khác nhau khi piston liên tục di chuyển lên xuống.
Trong trường hợp động cơ tuabin, bốn bước tương tự cũng xảy ra cùng một lúc nhưng ở những nơi khác nhau. Do sự khác biệt cơ bản này, tuabin có nhiều bộ phận động cơ khác nhau được gọi là:
Phần đầu vào
Phần máy nén
Phần đốt
Phần tuabin và ống xả.
Phần tuabin của động cơ chịu trách nhiệm tạo ra công suất trục có thể sử dụng như một đầu ra được sử dụng để dẫn động cánh quạt. Ngoài ra, nó phải được cung cấp năng lượng để điều khiển máy nén và các phụ kiện động cơ. Điều này được thực hiện bằng cách tiếp xúc với nhiệt độ cao, áp suất, khí vận tốc được chuyển đổi từ năng lượng khí sang năng lượng cơ học dưới dạng công suất trục.
Các thành phần và nguyên lý tuabin khí
Khối lượng không khí được cung cấp phải rất cao, được cho là cung cấp cho tuabin để tạo ra công suất cần thiết. Không khí được cung cấp được thực hiện với sự trợ giúp của máy nén chiết xuất không khí và đưa nó vào động cơ nơi nó được ép để cung cấp không khí áp suất cao cho tuabin. Vai trò của máy nén là chuyển đổi năng lượng cơ học từ tuabin sang năng lượng khí dưới dạng áp suất hoặc nhiệt độ.
Trong trường hợp máy nén và tuabin có hiệu suất 100% thì máy nén sẽ cung cấp tất cả không khí cần thiết cho tuabin và đồng thời, tuabin sẽ cung cấp năng lượng cần thiết để điều khiển máy nén. Trong trường hợp này, chỉ có một máy chuyển động vĩnh cửu sẽ tồn tại dưới dạng tổn thất ma sát và sự kém hiệu quả của hệ thống cơ học không cho phép máy chuyển động vĩnh viễn hoạt động bình thường.
Ngoài ra, một số năng lượng bổ sung cũng sẽ cần thiết ngoài không khí để đáp ứng cho những tổn thất đang gây ra. Công suất đầu ra cần thiết là từ động cơ nằm ngay ngoài máy nén; Do đó, cần thêm nhiều năng lượng hơn vào không khí để tạo ra năng lượng dư thừa. Năng lượng hóa học từ nhiên liệu được đốt cháy và được chuyển đổi thành năng lượng khí dưới dạng nhiệt độ cao và vận tốc cao vì không khí cần phải đi qua chính bộ đốt. Năng lượng khí được chuyển đổi một lần nữa thành năng lượng cơ học của tuabin cung cấp năng lượng để dẫn động máy nén và trục.
Phát hiện hiện tượng xâm thực bơm thông qua phân tích rung động
466
Phát hiện hiện tượng xâm thực (cavitation) bơm thông qua phân tích rung động
1- Cavitation là gì (Tóm tắt)
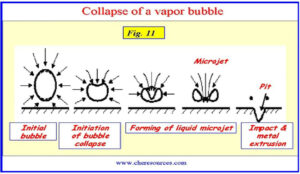
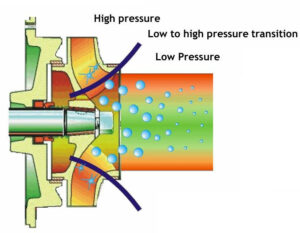
Khi chất lỏng đi vào mắt bánh công tác, vận tốc của nó tăng lên làm giảm áp suất (nguyên lý Bernoulli).Nếu áp suất chất lỏng giảm xuống quá thấp, một số chất lỏng sẽ bay hơi tạo thành bong bóng cuốn vào chất lỏng.
Khi những bong bóng hơi này di chuyển dọc theo cánh quạt đến vùng áp suất cao hơn áp suất hơi, chúng sẽ nhanh chóng sụp đổ.
Bong bóng xẹp xuống tạo ra áp suất cực lớn (10.000 psi) và sóng xung kích trên bánh công tác, vượt quá độ bền vật liệu của bánh công tác, dẫn đến mỏi bề mặt và tạo ra vết rỗ trên bề mặt.
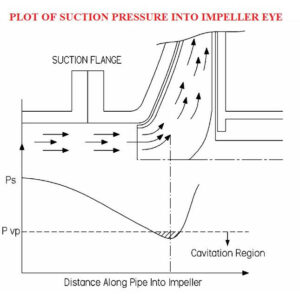
Áp suất cần thiết để vận hành máy bơm mà không gây ra hiện tượng xâm thực được gọi là cột áp hút dương thực (NPSH).Đầu áp suất có sẵn ở đầu vào máy bơm phải vượt quá NPSH yêu cầu ở một mức nhất định, điều này phụ thuộc vào thiết kế thủy lực của máy bơm.(Bạn có thể đọc thêm về NPSHR, NPSH3, NPSHA, Tốc độ hút cụ thể và Biên NPSH)
Xâm thực có tác dụng phá hủy máy bơm và sẽ dẫn đến hư hỏng cánh quạt, mất cân bằng, hỏng ổ trục, hỏng phốt trục, mất hiệu suất bơm, tiếng ồn, độ rung cao, v.v.
2- Phát hiện cavitation thông qua phân tích rung động
Tiếng ồn cao do xâm thực có thể được xác định như thể máy bơm đang bơm sỏi.Tuy nhiên, phân tích rung động có thể được sử dụng để xác nhận hiện tượng xâm thực.
Như được thể hiện trong biểu đồ dạng sóng phổ và thời gian của máy bơm BB1 có bánh công tác 6 cánh bị hiện tượng xâm thực, những điều sau đây có thể xác nhận hiện tượng xâm thực của máy bơm:
1- Giá trị rung cao ở mức 1X (Tốc độ quay) và 6X (Tốc độ cánh gạt): Độ rung cao ở tốc độ cánh gạt có thể liên quan đến bất kỳ vấn đề về dòng chảy hoặc thủy lực nào ở máy bơm.Tốc độ cánh có thể được mô tả đơn giản là đối với mỗi một vòng quay của trục, số lần cánh cánh quạt sẽ chạm vào chất lỏng.Do đó, hiện tượng xâm thực là do các bong bóng vỡ ra với sóng xung kích cường độ cao nên cứ mỗi vòng quay trục, các bong bóng sẽ xẹp xuống n lần (tùy thuộc vào số lượng cánh), gây ra giá trị rung động cao ở tần số cụ thể này.
2- Tầng tiếng ồn sẽ tăng lên ở tần số truyền của cánh quạt, cũng như ở tần số cao do kích thích cộng hưởng.
3- Dạng sóng thời gian (Gia tốc so với Biểu đồ thời gian) sẽ hiển thị các đợt năng lượng ngẫu nhiên.Bạn nên ghi lại các rung động trong khoảng 10 giây vì các đợt bùng phát năng lượng có thể cách nhau 1-3 giây.
Tóm tắt: Các nhà nghiên cứu đã thực hiện một khám phá đột phá liên kết các chất gây ô nhiễm môi trường với việc giảm khoảng thời gian hạnh phúc cảm xúc. Bằng cách sử dụng một công cụ đánh giá rủi ro mới, nghiên cứu tính toán việc mất tuổi thọ hạnh phúc (LHpLE) do tiếp xúc với các chất gây ung thư môi trường như radon, asen và vật chất hạt mịn và đau khổ tâm lý.
Đáng ngạc nhiên, tác động của ung thư đối với hạnh phúc cảm xúc được tìm thấy là không đáng kể, trong khi tiếp xúc với các chất gây ung thư và đau khổ tâm lý dẫn đến giảm đáng kể tuổi thọ hạnh phúc. Nghiên cứu này nhấn mạnh tầm quan trọng của các chính sách môi trường nhằm giảm phơi nhiễm chất gây ô nhiễm để tăng cường hạnh phúc và sức khỏe cộng đồng.
Thông tin chính:
Nghiên cứu giới thiệu LHpLE như một biện pháp kết hợp giảm hạnh phúc và tăng tỷ lệ tử vong do tiếp xúc với rủi ro môi trường.
Các chất gây ung thư môi trường làm giảm tuổi thọ hạnh phúc cảm xúc lên tới 0,0064 năm, với đau khổ tâm lý có tác động lớn hơn đáng kể, làm giảm tuổi thọ hạnh phúc 0,97 năm.
Mặc dù có sự hiện diện của ung thư, các cá nhân không báo cáo sự giảm đáng kể hạnh phúc cảm xúc, nhấn mạnh ảnh hưởng lớn hơn của các yếu tố môi trường và đau khổ tâm lý đối với sức khỏe tổng thể.
Nguồn: Đại học Osaka
Nếu cải thiện quan điểm của bạn về cuộc sống thực sự đơn giản như “đừng lo lắng, hãy hạnh phúc”, thì việc giữ tinh thần của bạn sẽ là một miếng bánh. Thật không may, nó không đơn giản như vậy, vì vô số yếu tố ngoài tầm kiểm soát của chúng ta có thể ảnh hưởng đến tâm trạng của chúng ta.
Trong một nghiên cứu được công bố vào tháng Ba trong Nghiên cứu Môi trường, các nhà nghiên cứu từ Đại học Osaka đã tiết lộ rằng các chất gây ô nhiễm trong môi trường có thể có ảnh hưởng đến sức khỏe tình cảm tuổi thọ của chúng ta.
“Phát hiện của chúng tôi cho thấy rằng việc tiếp xúc với chất gây ung thư và đau khổ tâm lý làm giảm đáng kể hạnh phúc suốt đời”, Murakami nói. Tín dụng: Tin tức khoa học thần kinh
Một công cụ đánh giá rủi ro được phát triển gần đây đã định nghĩa tuổi thọ hạnh phúc là tuổi thọ mà một người trải qua hạnh phúc cảm xúc chủ quan, trong khi mất tuổi thọ hạnh phúc (LHpLE) được định nghĩa là giảm thời gian trải nghiệm cảm xúc tích cực trong cuộc sống của một cá nhân. LHpLE được tính toán bằng cách kết hợp cả việc giảm hạnh phúc và tăng tỷ lệ tử vong liên quan đến phơi nhiễm rủi ro.
“Trước đây chúng tôi đã sử dụng chỉ số LHpLE để đánh giá tâm lý đau khổ và nguy cơ ung thư liên quan đến phơi nhiễm phóng xạ sau vụ tai nạn nhà máy điện hạt nhân Fukushima Daiichi, trong số các tình huống khác”, tác giả chính của nghiên cứu Michio Murakami cho biết.
Tuy nhiên, công cụ này chưa được sử dụng để đánh giá tác động của ung thư hoặc tiếp xúc với các chất gây ung thư môi trường đối với hạnh phúc”.
Để giải quyết vấn đề này, các nhà nghiên cứu đã khảo sát người Nhật để xác định hạnh phúc trung bình của họ theo độ tuổi và giới tính, đồng thời đánh giá liệu ung thư có làm giảm hạnh phúc cảm xúc hay không. Sau đó, LHpLE được tính toán để tiếp xúc với các tác nhân gây ung thư môi trường phổ biến ở Nhật Bản, cũng như đau khổ tâm lý, cho phép so sánh các loại phơi nhiễm rủi ro khác nhau.
“Kết quả thật hấp dẫn”, Shuhei Nomura, tác giả trẻ giải thích. “Chúng tôi thấy rằng hạnh phúc cảm xúc không giảm đáng kể ở những người bị ung thư, cũng không có bất kỳ mối liên hệ đáng kể nào giữa hạnh phúc cảm xúc và loại, tiền sử hoặc giai đoạn ung thư.”
Nhìn chung, tiếp xúc với các chất gây ung thư môi trường làm giảm tuổi thọ hạnh phúc cảm xúc 0,0064 năm đối với radon, 0,0026 năm đối với asen và 0,00086 năm đối với vật chất hạt mịn trong không khí, do tỷ lệ tử vong của chúng. Sự suy giảm hạnh phúc cảm xúc thậm chí còn rõ rệt hơn đối với đau khổ tâm lý, dẫn đến LHpLE là 0,97 năm.
“Phát hiện của chúng tôi cho thấy rằng việc tiếp xúc với chất gây ung thư và đau khổ tâm lý làm giảm đáng kể hạnh phúc suốt đời”, Murakami nói.
Với sự giảm rõ ràng về tuổi thọ hạnh phúc cảm xúc liên quan đến chất gây ung thư, những phát hiện từ nghiên cứu này cho thấy các chính sách môi trường nên tập trung vào việc giảm tiếp xúc với các hóa chất này. Áp dụng sự hiểu biết này vào các chính sách y tế công cộng có thể giúp mọi người sống lâu hơn, hạnh phúc hơn.
Về tin tức nghiên cứu khoa học thần kinh và tâm lý học môi trường này
Tác giả: Saori Obayashi Nguồn: Đại học Osaka Sự tiếp xúc: Saori Obayashi – Đại học
Osaka Hình ảnh: Hình ảnh được ghi nhận cho Tin tức khoa học thần kinh
Phát triển nhanh chóng đã giúp những con khủng long sớm nhất và các loài bò sát cổ đại khác phát triển mạnh mẽ sau hậu quả của sự tuyệt chủng hàng loạt
368
Phát triển nhanh chóng đã giúp những con khủng long sớm nhất và các loài bò sát cổ đại khác phát triển mạnh mẽ sau hậu quả của sự tuyệt chủng hàng loạt
Eoraptor lunensis sống cách đây khoảng 230 triệu năm, vào thời điểm khủng long còn nhỏ và hiếm. Jordan Harris lịch sự của Kristi Curry Rogers, CC BY-SA
Có thể khó tưởng tượng, nhưng ngày xửa ngày xưa, khủng long không thống trị thế giới của chúng. Khi chúng mới bắt nguồn, chúng chỉ là những động vật ăn thịt nhỏ, hai chân bị lu mờ bởi một loạt các loài bò sát khác.
Làm thế nào mà họ đến để cai trị?
Các đồng nghiệp của tôi và tôi gần đây đã nghiên cứu xương hóa thạch của những con khủng long được biết đến sớm nhất và các đối thủ không phải khủng long của chúng để so sánh tốc độ tăng trưởng của chúng. Chúng tôi muốn tìm hiểu xem những con khủng long đầu tiên có đặc biệt theo cách chúng phát triển hay không – và liệu điều này có thể giúp chúng có chỗ đứng trong thế giới thay đổi nhanh chóng của chúng hay không.
Nhưng trong nháy mắt thời gian địa chất, trong khoảng thời gian khoảng 60.000 năm, các nhà khoa học ước tính 95% tất cả các sinh vật sống đã tuyệt chủng. Được gọi là sự tuyệt chủng Permi hoặc Great Dying, nó là sự kiện tuyệt chủng hàng loạt lớn nhất trong năm sự kiện tuyệt chủng hàng loạtđược biết đến trên Trái đất.
Trong khoảng trống sinh thái sau sự kiện tuyệt chủng hàng loạt, trên sân khấu Trái đất chữa bệnh, tổ tiên của khủng long lần đầu tiên tiến hóa – cùng với tổ tiên của ếch, kỳ nhông, thằn lằn, rùa và động vật có vú ngày nay. Đó là buổi bình minh của kỷ Trias, kéo dài từ 252 triệu năm trước đến 201 triệu năm trước.
Nói chung, những sinh vật sống sót sau Great Dying không đặc biệt đáng chú ý. Một nhóm động vật, được gọi là Archosauria, bắt đầu với các kế hoạch cơ thể tương đối nhỏ và đơn giản. Chúng là những người ăn linh hoạt và có thể sống trong nhiều điều kiện môi trường khác nhau.
Archosaurs cuối cùng chia thành hai bộ lạc – một nhóm bao gồm cá sấu hiện đại và họ hàng cổ xưa của chúng và nhóm thứ hai bao gồm các loài chim hiện đại, cùng với tổ tiên khủng long của chúng.
Nhóm thứ hai này đi bằng ngón chân và có cơ bắp chân to. Họ cũng có thêm các kết nối giữa xương lưng và xương hông cho phép họ di chuyển hiệu quả trong thế giới mới.
Thay vì cạnh tranh trực tiếp với các loài archosaur khác, có vẻ như nhóm tổ tiên khủng long này đã khai thác các hốc sinh thái khác nhau – có thể bằng cách ăn các loại thực phẩm khác nhau hoặc sống ở các khu vực địa lý hơi khác nhau. Nhưng ban đầu, những con archosaur giống khủng long ít đa dạng hơn nhiều so với tổ tiên cá sấu mà chúng sống cùng.
Dần dần, dòng dõi khủng long tiếp tục tiến hóa. Phải mất hàng chục triệu năm trước khi khủng long trở nên phong phú đủ để bộ xương của chúng xuất hiện trong hồ sơ hóa thạch.
Công viên tỉnh Ischigualasto ở tỉnh San Juan, Argentina, nơi phát hiện hóa thạch khủng long sớm nhất.Cà ri Kristi Rogers, CC BY-SA
Những con khủng long đầu tiên này chỉ đại diện cho một phần nhỏ động vật được tìm thấy từ khoảng thời gian đó. Trong thế giới cổ đại này, những con archosaur giống cá sấu đứng đầu. Chúng có một loạt các hình dạng cơ thể, kích cỡ và lối sống, dễ dàng vượt qua những con khủng long đầu tiên trong cuộc đua đa dạng.
Mãi cho đến gần cuối kỷ Trias, khi một sự kiện tuyệt chủng hàng loạt khác do núi lửa gây ra xảy ra, khủng long mới có được cơ hội may mắn.
Các cộng tác viêncủa tôitừ Đại học Nacional de San Juan, Argentina và tôi tự hỏi liệu sự trỗi dậy của khủng long có thể được củng cố, một phần, bởi tốc độ phát triển của chúng hay không. Chúng ta biết, thông qua nghiên cứu bằng kính hiển vi về xương hóa thạch, những con khủng long sau này có tốc độ tăng trưởng nhanh – nhanh hơn nhiều so với các loài bò sát hiện đại. Nhưng chúng tôi không biết liệu điều đó có đúng với những con khủng long đầu tiên hay không.
Chúng tôi quyết định kiểm tra các mẫu vi mô được bảo quản trong xương đùi từ năm loài khủng long được biết đến sớm nhất và so sánh chúng với sáu loài bò sát không phải khủng long và một họ hàng sớm của động vật có vú. Tất cả các hóa thạch chúng tôi nghiên cứu đến từ khoảng thời gian 2 triệu năm trong Hệ tầng Ischigualasto của Argentina.
Mô xương Eoraptor dưới kính hiển vi ánh sáng phân cực cho thấy bằng chứng về sự tăng trưởng nhanh chóng, liên tục – phổ biến cho cả loài khủng long sớm nhất và nhiều loài cùng thời không phải khủng long của chúng.Kristi Curry Rogers, CC BY-ND
Xương là một kho lưu trữ lịch sử tăng trưởng bởi vì, ngay cả trong hóa thạch, chúng ta có thể thấy những khoảng trống nơi các mạch máu và tế bào đục lỗ mô khoáng hóa. Khi chúng ta nhìn vào các tính năng này dưới kính hiển vi, chúng ta có thể thấy chúng được tổ chức như thế nào. Sự tăng trưởng càng chậm xảy ra, các tính năng vi mô có tổ chức sẽ càng nhiều. Với sự tăng trưởng nhanh hơn, các tính năng vi mô của xương càng vô tổ chức.
Chúng tôi phát hiện ra những con khủng long đầu tiên phát triển liên tục, không dừng lại cho đến khi chúng đạt đến kích thước đầy đủ. Và họ thực sự đã có tốc độ tăng trưởng cao, ngang bằng và, đôi khi, thậm chí còn nhanh hơn so với con cháu của họ. Nhưng nhiều người đương thời không phải khủng long của họ cũng vậy. Có vẻ như hầu hết các loài động vật sống trong hệ sinh thái Ischigualasto đều phát triển nhanh chóng, với tốc độ giống với động vật có vú và chim sống hơn là động vật bò sát sống.
Dữ liệu của chúng tôi cho phép chúng tôi thấy sự khác biệt tinh tế giữa các động vật có liên quan chặt chẽ và những động vật chiếm các hốc sinh thái tương tự. Nhưng trên hết, dữ liệu của chúng tôi cho thấy tăng trưởng nhanh là một chiến lược sinh tồn tuyệt vời sau hậu quả của sự hủy diệt hàng loạt.
Các nhà khoa học vẫn chưa biết chính xác điều gì đã khiến khủng long và tổ tiên cổ đại của chúng có thể sống sót qua hai trong số những cuộc tuyệt chủng rộng lớn nhất mà Trái đất từng trải qua. Chúng tôi vẫn đang nghiên cứu khoảng thời gian quan trọng này, xem xét các chi tiết như chân và cơ thể được xây dựng để vận động hiệu quả, thẳng đứng, những thay đổi tiềm năng trong cách những con khủng long đầu tiên có thể thở và cách chúng lớn lên. Chúng tôi nghĩ rằng có lẽ tất cả những yếu tố này, kết hợp với may mắn, cuối cùng đã cho phép khủng long trỗi dậy và cai trị.
Vâng, đại loại. Không giống như cách bạn hoặc tôi có thể hét lên. Thay vào đó, chúng phát ra tiếng nổ hoặc tiếng nhấp chuột ở tần số siêu âm ngoài phạm vi thính giác của con người tăng lên khi cây bị căng thẳng.
Điều này, theo một nghiên cứu được công bố vào năm 2023, có thể là một trong những cách mà thực vật truyền đạt nỗi đau của chúng với thế giới xung quanh.
“Ngay cả trong một cánh đồng yên tĩnh, thực sự có những âm thanh mà chúng ta không nghe thấy, và những âm thanh đó mang thông tin. Có những loài động vật có thể nghe thấy những âm thanh này, vì vậy có khả năng rất nhiều tương tác âm thanh đang xảy ra”, nhà sinh vật học tiến hóa Lilach Hadany của Đại học Tel Aviv ở Israel cho biết.
“Thực vật tương tác với côn trùng và các động vật khác mọi lúc, và nhiều sinh vật trong số này sử dụng âm thanh để giao tiếp, vì vậy sẽ rất không tối ưu nếu thực vật không sử dụng âm thanh.”
Thực vật bị căng thẳng không thụ động như bạn nghĩ. Chúng trải qua một số thay đổi khá ấn tượng, một trong những thay đổi dễ phát hiện nhất (ít nhất là đối với con người chúng ta) là sự giải phóng một số mùi hương khá mạnh mẽ. Chúng cũng có thể thay đổi màu sắc và hình dạng của chúng.
Tuy nhiên, liệu thực vật có phát ra các loại tín hiệu khác – chẳng hạn như âm thanh – hay không vẫn chưa được khám phá đầy đủ. Vài năm trước, Hadany và các đồng nghiệp của cô đã phát hiện ra rằng thực vật có thể phát hiện âm thanh. Câu hỏi hợp lý tiếp theo cần đặt ra là liệu họ có thể sản xuất nó hay không.
Để tìm hiểu, họ đã ghi lại cây cà chua và thuốc lá trong một số điều kiện. Đầu tiên, họ ghi lại các nhà máy không bị căng thẳng, để có được đường cơ sở. Sau đó, họ ghi lại những cây bị mất nước và những cây đã bị cắt thân. Những bản ghi âm này diễn ra đầu tiên trong buồng âm thanh cách âm, sau đó trong môi trường nhà kính bình thường.
Sau đó, họ đào tạo một thuật toán học máy để phân biệt giữa âm thanh được tạo ra bởi thực vật không bị căng thẳng, cây cắt và cây mất nước.
Âm thanh thực vật phát ra giống như tiếng nổ hoặc tiếng nhấp chuột ở tần số quá cao để con người có thể phát ra, có thể phát hiện trong bán kính hơn một mét (3,3 feet). Thực vật không bị căng thẳng không gây ra nhiều tiếng ồn; Họ chỉ đi chơi, lặng lẽ làm việc thực vật của họ.
Ngược lại, thực vật bị căng thẳng ồn ào hơn nhiều, phát ra trung bình khoảng 40 lần nhấp mỗi giờ tùy thuộc vào loài. Và thực vật thiếu nước có một cấu hình âm thanh đáng chú ý. Chúng bắt đầu nhấp chuột nhiều hơn trước khi chúng có dấu hiệu mất nước rõ ràng, leo thang khi cây phát triển khô hơn, trước khi lắng xuống khi cây khô héo.
Thuật toán đã có thể phân biệt giữa những âm thanh này, cũng như các loài thực vật phát ra chúng. Và nó không chỉ là cây cà chua và thuốc lá. Nhóm nghiên cứu đã thử nghiệm nhiều loại thực vật khác nhau và thấy rằng sản xuất âm thanh dường như là một hoạt động thực vật khá phổ biến. Lúa mì, ngô, nho, xương rồng và henbit đều được ghi lại gây ra tiếng ồn.
Nhưng vẫn còn một vài ẩn số. Ví dụ, không rõ âm thanh đang được tạo ra như thế nào. Trong nghiên cứu trước đây, thực vật mất nước đã được tìm thấy trải qua xâm thực, một quá trình theo đó bọt khí ở dạng thân, mở rộng và sụp đổ. Điều này, trong tiếng nứt đốt ngón tay của con người, tạo ra một tiếng nổ có thể nghe được; Một cái gì đó tương tự có thể đang xảy ra với thực vật.
Chúng tôi cũng chưa biết liệu các điều kiện đau khổ khác có thể gây ra âm thanh hay không. Tác nhân gây bệnh, tấn công, tiếp xúc với tia cực tím, nhiệt độ khắc nghiệt và các điều kiện bất lợi khác cũng có thể khiến cây bắt đầu bật ra như bọc bong bóng.
Cũng không rõ liệu sản xuất âm thanh có phải là sự phát triển thích nghi ở thực vật hay chỉ là điều gì đó xảy ra. Tuy nhiên, nhóm nghiên cứu đã chỉ ra rằng một thuật toán có thể học cách xác định và phân biệt giữa các âm thanh thực vật. Chắc chắn có thể các sinh vật khác cũng có thể làm như vậy.
Ngoài ra, những sinh vật này có thể đã học cách phản ứng với tiếng ồn của thực vật đau khổ theo nhiều cách khác nhau.
“Ví dụ, một con sâu bướm có ý định đẻ trứng trên cây hoặc động vật có ý định ăn thực vật có thể sử dụng âm thanh để giúp hướng dẫn quyết định của chúng”, Hadany nói.
Đối với con người chúng ta, ý nghĩa là khá rõ ràng; Chúng ta có thể điều chỉnh các cuộc gọi đau khổ của cây khát và tưới nước cho chúng trước khi nó trở thành một vấn đề.
“Bây giờ chúng ta biết rằng thực vật phát ra âm thanh, câu hỏi tiếp theo là – ‘ai có thể đang lắng nghe?'” Hadany nói.
“Chúng tôi hiện đang điều tra phản ứng của các sinh vật khác, cả động vật và thực vật, đối với những âm thanh này và chúng tôi cũng đang khám phá khả năng xác định và giải thích âm thanh trong môi trường hoàn toàn tự nhiên.”
Một phương pháp để phát hiện lỗi sản xuất tiên tiến thông qua học tập tự giám sát trên hình ảnh X-quang
320
Một phương pháp để phát hiện lỗi sản xuất tiên tiến thông qua học tập tự giám sát trên hình ảnh X-quang
Tóm lược
Trong kiểm soát chất lượng công nghiệp, đặc biệt là trong lĩnh vực phát hiện lỗi sản xuất, học sâu đóng vai trò ngày càng quan trọng. Tuy nhiên, hiệu quả của các mô hình tiên tiến này thường bị cản trở bởi nhu cầu về các bộ dữ liệu có chú thích quy mô lớn. Hơn nữa, các bộ dữ liệu này chủ yếu dựa trên hình ảnh RGB, rất khác với hình ảnh tia X. Giải quyết hạn chế này, nghiên cứu của chúng tôi đề xuất một phương pháp kết hợp các kỹ thuật tiền đào tạo tự giám sát theo miền cụ thể bằng cách sử dụng hình ảnh tia X để cải thiện khả năng phát hiện khuyết tật trong sản xuất sản phẩm. Chúng tôi sử dụng hai phương pháp tiền đào tạo, SimSiam và SimMIM, để tinh chỉnh trích xuất tính năng từ hình ảnh sản xuất. Giai đoạn tiền đào tạo được thực hiện bằng cách sử dụng bộ dữ liệu công nghiệp gồm 27.901 hình ảnh X-quang không được dán nhãn từ dây chuyền sản xuất. Chúng tôi phân tích hiệu suất của pretraining so với các phương pháp dựa trên chuyển giao học tập trong một kịch bản phát hiện lỗi phức tạp bằng cách sử dụng mô hình R-CNN nhanh hơn. Chúng tôi tiến hành đánh giá trên cả bộ dữ liệu công nghiệp độc quyền và bộ dữ liệu GDXray có sẵn công khai. Các phát hiện cho thấy các mô hình được đào tạo trước với hình ảnh X-quang miền cụ thể luôn hoạt động tốt hơn các mô hình được khởi tạo với trọng số ImageNet. Đáng chú ý, các mô hình Swin Transformer cho thấy kết quả vượt trội trong các kịch bản giàu dữ liệu được gắn nhãn, trong khi xương sống CNN hiệu quả hơn trong môi trường dữ liệu hạn chế. Hơn nữa, chúng tôi nhấn mạnh khả năng nâng cao của các mô hình được đào tạo trước bằng hình ảnh tia X trong việc phát hiện các khuyết tật nghiêm trọng, rất quan trọng để đảm bảo an toàn trong môi trường công nghiệp. Nghiên cứu của chúng tôi cung cấp bằng chứng đáng kể về lợi ích của việc học tự giám sát trong phát hiện lỗi sản xuất, cung cấp nền tảng vững chắc cho nghiên cứu sâu hơn và ứng dụng thực tế trong kiểm soát chất lượng công nghiệp.
Trong những năm qua, nghiên cứu sâu rộng đã được tiến hành để tăng cường kiểm tra trực quan các sản phẩm sản xuất bằng hình ảnh X-quang. Trọng tâm chính là phát triển các quy trình tự động có khả năng xác định các sản phẩm bị lỗi. Trên thực tế, phân tích thủ công từng phần không chỉ là một nhiệm vụ lặp đi lặp lại và mệt mỏi đối với người vận hành, mà độ chính xác của chúng cũng có thể có xu hướng giảm theo thời gian [1]. Ngược lại, các phương pháp tiếp cận dựa trên dữ liệu không chỉ đảm bảo hiệu suất đồng đều trong thời gian dài mà còn giảm thiểu hiệu quả rủi ro lỗi của con người. Do đó, chúng có thể hỗ trợ đáng kể trong quá trình ra quyết định của người vận hành.
Những tiến bộ gần đây trong các phương pháp tiếp cận dựa trên học sâu đã nổi lên như là giải pháp hàng đầu cho nhiều nhiệm vụ trên nhiều lĩnh vực [2]. Cụ thể trong bối cảnh phát hiện lỗi sản xuất, các kỹ thuật này hiện được coi là hiện đại, vượt trội hơn đáng kể so với các phương pháp truyền thống [3,4,5]. Tuy nhiên, hiệu suất của chúng được điều chỉnh bởi một điều kiện quan trọng: bản chất đói dữ liệu của chúng. Những cách tiếp cận này yêu cầu bộ dữ liệu mở rộng của hình ảnh được gắn nhãn trong quá trình đào tạo để tìm hiểu các biểu diễn trực quan hiệu quả. Do đó, hiệu quả của chúng có thể giảm đáng kể khi chỉ có một số lượng hình ảnh hạn chế, làm nổi bật một thách thức quan trọng trong ứng dụng của chúng. Thách thức này thậm chí còn trở nên đáng chú ý hơn trong việc phát hiện lỗi vì việc thu thập các bộ dữ liệu rộng rãi, được dán nhãn chính xác tỏ ra đặc biệt khó khăn trong môi trường công nghiệp.
Một giải pháp tiềm năng để giảm thiểu các yêu cầu dữ liệu là áp dụng học tập chuyển giao. Cách tiếp cận này về cơ bản liên quan đến việc tận dụng kiến thức thu được từ các vấn đề được xác định rộng rãi và áp dụng nó vào các nhiệm vụ cụ thể hơn, được nhắm mục tiêu. Đối với các mô hình thị giác, đào tạo trước trên các bộ dữ liệu mở rộng như ImageNet [6] giúp tăng cường khả năng của chúng cho các nhiệm vụ xuôi dòng khác nhau. Tuy nhiên, mặc dù hiệu quả đã được chứng minh của các mô hình này trong việc phát hiện lỗi sản xuất, hiệu suất có thể bị ảnh hưởng bởi (1) sự chênh lệch giữa hình ảnh ImageNet và hình ảnh X-quang và (2) sự thiên vị tiềm ẩn của các mô hình này đối với các danh mục cụ thể có trong tập dữ liệu.
Tuy nhiên, nhu cầu về một bộ dữ liệu được gắn nhãn trong các phương pháp pretraining này thường gây ra một nút cổ chai trong việc phát triển các mô hình học sâu. Học tập tự giám sát nổi lên như một giải pháp, cho phép trích xuất các tính năng quan trọng từ hình ảnh mà không cần dựa vào dữ liệu được dán nhãn và do đó sử dụng hiệu quả khối lượng lớn dữ liệu có sẵn. Trong bối cảnh phát hiện lỗi sản xuất, các phương pháp tự giám sát cho phép sử dụng các bộ dữ liệu lớn về hình ảnh X-quang không được dán nhãn, phổ biến trong các cơ sở công nghiệp. Điều này tạo điều kiện cho việc đào tạo một mô hình lão luyện trong việc hiểu các biểu diễn hình ảnh tia X và đáng tin cậy trong việc trích xuất các tính năng phù hợp nhất. Sau đó, mô hình trở thành xương sống phù hợp cho các nhiệm vụ xuôi dòng liên quan đến bộ dữ liệu tia X được dán nhãn, tăng cường khả năng ứng dụng và hiệu quả của nó trong việc xác định lỗi chính xác.
Đóng góp chính của công việc này là giới thiệu một phương pháp mới để phát hiện khuyết tật trong các bộ phận sản xuất, nơi chúng tôi sử dụng các phương pháp tiền đào tạo chuyên biệt trên hình ảnh tia X để phát triển các mô hình có khả năng trích xuất tính năng nâng cao. Bằng cách thực hiện giai đoạn tiền đào tạo với hình ảnh từ lĩnh vực sản xuất cụ thể, các mô hình của chúng tôi phát triển thành các trình trích xuất tính năng rất lão luyện, cho thấy sự cải thiện đáng kể trong việc xác định các tính năng liên quan đến nhiệm vụ so với các mô hình được khởi tạo bằng trọng số ImageNet. Phương pháp này được xác nhận bởi hiệu suất mạnh mẽ của các mô hình này trong các nhiệm vụ phát hiện lỗi trong bối cảnh sản xuất, như được thấy thông qua các đánh giá cả trên bộ dữ liệu điểm chuẩn công khai và trong môi trường công nghiệp trong thế giới thực. Việc xác nhận như vậy nhấn mạnh hiệu quả thực tế và tầm quan trọng của phương pháp tiếp cận của chúng tôi trong các tình huống mà việc xác định lỗi chính xác là rất quan trọng. Thông qua công việc này, chúng tôi đóng góp vào lĩnh vực phát hiện lỗi sản xuất bằng cách giới thiệu cách đào tạo chuyên dụng có thể trích xuất hiệu quả các tính năng liên quan từ hình ảnh X-quang, do đó cung cấp những hiểu biết mới về việc áp dụng công nghệ này trong môi trường công nghiệp.
2. Công việc liên quan
2.1. Phát hiện lỗi sản xuất
Nhiều nỗ lực đã được thực hiện trong những năm qua để tự động hóa nhiệm vụ phát hiện khuyết tật trong sản xuất bằng phương pháp thị giác máy tính. Hiện nay, phát hiện lỗi sản xuất là một vấn đề được thiết lập tốt trong lĩnh vực thị giác máy tính và đã được áp dụng rộng rãi trong nhiều quy trình kiểm soát chất lượng công nghiệp [7,8,9]. Những nỗ lực ban đầu trong phát hiện khuyết tật đã sử dụng so sánh hình ảnh [10] và Biến đổi Fourier [11] để xác định các khiếm khuyết, tiếp theo là các kỹ thuật thống kê để trích xuất tính năng [8,12]. Các tính năng này sau đó được phân loại bằng cách sử dụng máy học để phân biệt giữa các mặt hàng bị lỗi và không bị lỗi. Tuy nhiên, việc trích xuất tính năng thủ công này là sản phẩm cụ thể và không được áp dụng phổ biến, hạn chế khả năng chuyển giao kiến thức đã học.
Sự xuất hiện của các phương pháp tiếp cận dựa trên học sâu đã cải thiện độ chính xác trong kiểm soát chất lượng sản xuất [3,4,5,13,14,15]. Cấu trúc phức tạp của chúng có thể giữ lại và tự động tìm hiểu thông tin chứa trong ảnh, tạo điều kiện thuận lợi hơn cho việc xử lý hình ảnh so với các kỹ thuật trước đây. Các mô hình dựa trên học sâu được xây dựng theo cách từ đầu đến cuối nên các quy trình thủ công không bắt buộc phải trích xuất các tính năng phân biệt đối xử [3,16]. Trên thực tế, quá trình trích xuất tính năng được thực hiện tự động từ hình ảnh thô, tiếp theo là một đầu phân loại tìm hiểu ranh giới giữa các tính năng bị lỗi và không bị lỗi.
Trong những năm gần đây, nhiều nghiên cứu đã sử dụng Mạng nơ-ron tích chập sâu (CNN) để phân loại cấp độ hình ảnh, phân biệt hiệu quả giữa hình ảnh sản xuất bị lỗi và không bị lỗi [1,8]. Các công trình này tập trung vào việc tinh chỉnh quy trình trích xuất tính năng, coi nó rất quan trọng để phát triển một máy dò khuyết tật hiệu quả. Kuo et al. [1] đã so sánh các xương sống trích xuất tính năng khác nhau trên hình ảnh bề mặt với các khuyết tật phun cát. Ngoài ra, Wang et al. [17] đã sử dụng mô-đun tự chú ý để trích xuất và phân loại các tính năng từ các khuyết tật nhỏ.
Tuy nhiên, mục đích của việc phát hiện lỗi không chỉ là phân loại sản phẩm ở cấp độ hình ảnh mà còn xác định vị trí các khuyết tật trong toàn bộ hình ảnh khi sản phẩm bị lỗi. Do đó, nghiên cứu đã chuyển sang ứng dụng các mô hình phát hiện đối tượng để kết hợp thông tin vị trí [3,13,14,15,18]. Ferguson et al. [3] đã áp dụng Faster R-CNN [19] cho bộ dữ liệu điểm chuẩn GDXray [20], thu được kết quả khả quan. Ngay sau đó, họ đã cải thiện kết quả của mình bằng cách áp dụng Masked R-CNN [4] được đào tạo trước trên bộ dữ liệu COCO [21]. Du et al. [13] đã đề xuất một số cải tiến cho R-CNN nhanh hơn để phát hiện lỗi trong các sản phẩm sản xuất ô tô, bao gồm Mạng kim tự tháp tính năng [22] (FPN), RoIAlign [23] và các kỹ thuật tăng cường dữ liệu. Hơn nữa, Wang et al. [17] là những người đầu tiên tích hợp các cơ chế tự chú ý với CNN, tăng cường phát hiện lỗi hình ảnh bằng cách trích xuất các tính năng tinh tế từ các tính năng chung.
Thách thức chính đối với các phương pháp tiếp cận dựa trên deep learning là sự phụ thuộc của họ vào một khối lượng lớn hình ảnh để đạt được hiệu suất đáng tin cậy [24]. Thật vậy, áp dụng học tập chuyển giao với các mô hình được đào tạo trước cung cấp một bước ban đầu phù hợp [4]. Tuy nhiên, có một sự khác biệt đáng chú ý giữa hình ảnh X-quang và những hình ảnh thường được sử dụng trong đào tạo trước ImageNet; Hình ảnh tia X có thang độ xám và mô tả các bộ phận sản xuất cụ thể, tương phản với hình ảnh RGB của các vật thể và cảnh hàng ngày khác nhau từ ImageNet. Sự khác biệt này dẫn đến một sự thay đổi tên miền đáng kể.
Mặc dù đã có những tiến bộ đáng kể trong việc áp dụng nội địa hóa khuyết tật để phát hiện lỗi sản xuất, một lỗ hổng đáng chú ý tồn tại trong việc sử dụng học tập tự giám sát trên hình ảnh sản xuất tia X. Theo hiểu biết tốt nhất của chúng tôi, cách tiếp cận cụ thể này vẫn chưa được khám phá, đại diện cho một hướng đi đầy hứa hẹn để nâng cao độ chính xác và hiệu quả của việc phát hiện khuyết tật trong các cơ sở công nghiệp. Chúng tôi đưa ra giả thuyết rằng học tập tự giám sát, được áp dụng đặc biệt để sản xuất hình ảnh X-quang, có thể là một chiến lược hiệu quả để khắc phục sự phụ thuộc vào các bộ dữ liệu lớn, được dán nhãn trong học sâu. Bằng cách áp dụng phương pháp này để đào tạo trước, mục tiêu của chúng tôi là trích xuất và tinh chỉnh các tính năng tiêu biểu nhất nội tại cho miền cụ thể này, sau đó có thể nâng cao hiệu suất của các tác vụ phát hiện lỗi xuôi dòng. Do đó, sự tiến bộ này sẽ làm tăng hiệu quả và độ tin cậy của việc phát hiện khuyết tật trong các ứng dụng công nghiệp trong thế giới thực.
2.2. Học tự giám sát
Như đã đề cập, người ta thừa nhận rộng rãi rằng các thuật toán học sâu hiện tại đòi hỏi các bộ dữ liệu đào tạo quy mô lớn để tìm hiểu các biểu diễn dữ liệu nội tại và đạt được khả năng khái quát hóa thỏa đáng. Trong học tập có giám sát, dữ liệu được gắn nhãn là bắt buộc trong quá trình đào tạo, vì vậy các bộ dữ liệu lớn phải được chú thích. Đây có thể được xem là một nút thắt cổ chai vì quá trình ghi nhãn tốn thời gian và tốn kém, cũng như không khả thi trong một số lĩnh vực. Hơn nữa, các mô hình được đào tạo theo cách có giám sát phụ thuộc rất nhiều vào các nhãn được chú thích thủ công.
Hiện nay, học tự giám sát là một giải pháp thay thế phổ biến để học các biểu diễn trực quan của hình ảnh mà không có dữ liệu chú thích. Nó tận dụng số lượng lớn dữ liệu không được gắn nhãn có sẵn để đào tạo một mô hình giải quyết các nhiệm vụ lý do khác nhau. Trong quá trình này, mô hình tìm hiểu các tính năng hình ảnh vốn có có thể được sử dụng cho một số mục đích cuối cùng [25]. Như được đề xuất trong cuộc khảo sát của Liu et al. [26], các phương pháp học tập tự giám sát có thể được tóm tắt là dựa trên thế hệ [27], dựa trên tương phản [28,29] hoặc dựa trên GAN [30]. Cuộc khảo sát cho thấy các phương pháp tiếp cận dựa trên GAN và tạo ra kém hiệu quả trong các nhiệm vụ phân loại so với các phương pháp dựa trên tương phản. Do đó, vì phát hiện khuyết tật có thể được coi là một vấn đề phân loại cụ thể, phân tích của chúng tôi tập trung vào các kỹ thuật dựa trên tương phản tự giám sát.
Ý tưởng chính của cách tiếp cận tương phản là xây dựng một vấn đề phân biệt đối xử đơn giản dựa trên một nhiệm vụ lấy cớ giúp mô hình tìm hiểu các tính năng đại diện từ hình ảnh. Nhiệm vụ lấy cớ nhóm các hình ảnh thành các nhóm khác nhau với giả định rằng các hình ảnh từ cùng một nhóm giống nhau về mặt ngữ nghĩa trong khi hình ảnh từ các nhóm khác nhau thì không [25]. Theo đó, học tập tương phản cố gắng giảm thiểu khoảng cách giữa các đặc điểm hình ảnh từ cùng một nhóm (được gọi là cặp dương), do đó làm giảm sự tương đồng trong lớp và tối đa hóa khoảng cách giữa các đặc điểm hình ảnh từ các nhóm khác nhau (cặp âm), tăng sự tương đồng giữa các lớp.
Cố gắng xác định nhiệm vụ lấy cớ, Wu et al. [31] đã giới thiệu phân biệt đối xử phiên bản với ngân hàng bộ nhớ để đào tạo hiệu quả, nhấn mạnh tầm quan trọng của một số lượng lớn các mẫu âm tính để cải thiện hiệu suất. Khái niệm này đã được tinh chỉnh thêm bởi He et al. [28], người đã sử dụng bộ mã hóa động lượng và tăng cường dữ liệu để tạo ra các cặp dương từ cùng một hình ảnh. Chen et al. [29] đề xuất SimCLR, loại bỏ sự cần thiết của ngân hàng bộ nhớ và sử dụng các mẫu âm tính hàng loạt hiện tại để tính toán tổn thất tương phản, mặc dù yêu cầu kích thước lô lớn để có chất lượng biểu diễn tốt hơn. Các nghiên cứu tiếp theo tập trung vào tác động của âm bản cứng và cân bằng kích thước lô [32,33]. Grill et al. [34] đã giải quyết vấn đề kích thước lô lớn bằng cách chỉ dựa vào các cặp dương và tăng cường bộ mã hóa động lượng, mang lại sự mạnh mẽ trong các tình huống lô nhỏ hơn. Tuy nhiên, mô hình SimSiam của Chen et al. [35] đại diện cho một bước nhảy vọt với kiến trúc đơn giản hơn và tính năng stop-gradient độc đáo, hoạt động hiệu quả mà không cần mẫu âm, lô lớn hoặc bộ mã hóa động lượng.
Trong lĩnh vực học tập tự giám sát, một sự tiến hóa đáng kể đã được quan sát thấy với việc tích hợp Transformers vào thị giác máy tính, thoát khỏi sự phụ thuộc truyền thống vào các phương pháp tiếp cận dựa trên CNN [36]. Các mô hình này, nổi tiếng với khả năng nắm bắt các phụ thuộc quan hệ phức tạp trong chuỗi hình ảnh, đã cho thấy khả năng mở rộng đáng kể trong việc xử lý các mạng và bộ dữ liệu quy mô lớn [37]. Sự tiến bộ này đã dẫn đến sự phát triển của các kiến trúc tự chú ý phân cấp tập trung vào việc trích xuất các tính năng đa độ phân giải cần thiết cho các ứng dụng chi tiết như phát hiện lỗi [38,39,40].
Quá trình chuyển đổi sang Transformers trong tầm nhìn này phù hợp liền mạch với những tiến bộ rộng lớn hơn trong học tập tự giám sát. Vision Transformers, song song với các kỹ thuật NLP như mặt nạ mã thông báo của BERT [41], áp dụng các chiến lược tiền đào tạo tương tự. Bằng cách che các phần của hình ảnh và tái tạo chúng, phương pháp này cho phép học từ các bộ dữ liệu lớn, không được gắn nhãn, giảm sự phụ thuộc vào dữ liệu được chú thích [42]. Điều này phản ánh sự tiến bộ thống nhất trong việc khai thác dữ liệu không được gắn nhãn cho các tác vụ trực quan phức tạp, nhấn mạnh tầm quan trọng của các biểu diễn trực quan mạnh mẽ [43].
3. Vật liệu và phương pháp
Phần này cung cấp tổng quan chi tiết về phương pháp chúng tôi đã sử dụng để đạt được mục tiêu chính của mình: cải thiện hiệu suất phát hiện khuyết tật trong môi trường công nghiệp trong thế giới thực bằng cách sử dụng giai đoạn tiền đào tạo. Chúng tôi trình bày chi tiết và so sánh hai kỹ thuật tự giám sát được sử dụng trong phương pháp của chúng tôi, nhấn mạnh cách mỗi kỹ thuật góp phần tăng cường việc học các biểu diễn trực quan. Ngoài ra, chúng tôi thảo luận về tác động tiềm năng của chúng trong việc cải thiện nhận dạng khuyết tật trong các cơ sở công nghiệp.
3.1. Phương pháp luận của chúng tôi
Phương pháp của chúng tôi tập trung vào việc áp dụng các kỹ thuật học tập tự giám sát để xây dựng các máy dò khuyết tật cho sản xuất với mục tiêu nâng cao hiện trạng hiện đại trong phát hiện lỗi sản xuất. Nó nổi bật so với các phương pháp trước đây trong phát hiện lỗi sản xuất bằng cách khai thác các bộ dữ liệu lớn về hình ảnh X-quang không được dán nhãn, thường được tìm thấy trong các cơ sở công nghiệp, để đào tạo các máy dò khuyết tật theo cách tự giám sát.
Giai đoạn tiền đào tạo của phương pháp luận của chúng tôi liên quan đến việc phát triển các mô hình có khả năng tự động học và trích xuất các tính năng hình ảnh quan trọng từ hình ảnh X-quang, độc lập với dữ liệu được chú thích. Trong giai đoạn này, các mô hình được đào tạo theo cách tự giám sát trên bộ dữ liệu không được dán nhãn của hình ảnh sản xuất tia X. Trong các phần tiếp theo của bài viết này, chúng tôi trình bày chi tiết toàn diện hai kỹ thuật học tập tự giám sát riêng biệt. Những phương pháp này đã được lựa chọn đặc biệt vì hiệu quả đã được chứng minh và hiệu suất vượt trội trong các nhiệm vụ tiền đào tạo trước đó. Kết quả của khóa đào tạo, chúng tôi tận dụng các đặc điểm và mẫu vốn có trong những hình ảnh này, do đó cho phép các mô hình xác định các dị thường tinh tế nhưng quan trọng báo hiệu các khiếm khuyết. Ngoài ra, giai đoạn tiền đào tạo này không bị gánh nặng với chi phí thu thập dữ liệu cao. Chi phí đáng kể trong việc chuẩn bị dữ liệu thường phát sinh từ nhu cầu chú thích hình ảnh chính xác hơn là thu thập dữ liệu thô. Theo cách tiếp cận của chúng tôi, hình ảnh thô có thể được thu thập hiệu quả thông qua máy ảnh X-quang được tích hợp vào dây chuyền sản xuất, cho phép mua lại một bộ sản phẩm được sản xuất toàn diện.
Sau khi đào tạo trước khi tự giám sát, mô hình đóng vai trò như một bộ trích xuất tính năng tinh chỉnh cho các nhiệm vụ hạ nguồn cụ thể, đặc biệt là để phát hiện lỗi trong sản xuất. Cách tiếp cận này tận dụng tối đa khả năng cải thiện của mô hình để hiểu và giải thích các đặc điểm của hình ảnh X-quang. Sau đó, phù hợp với các phương pháp đã được thiết lập trong tài liệu [3,4,13], chúng tôi tích hợp trình trích xuất tính năng vào khung phát hiện đối tượng. Mô hình trải qua quá trình tinh chỉnh trên tập dữ liệu đích được chú thích cẩn thận, trong đó các khiếm khuyết được mô tả bằng cách sử dụng các hộp giới hạn hoặc chú thích pixel-wise, phân biệt rõ ràng chúng với nền hình ảnh. Trọng tâm trong giai đoạn tinh chỉnh này là đào tạo máy dò để định vị chính xác và xác định các đặc điểm khuyết tật trong toàn bộ hình ảnh, nâng cao độ chính xác của việc phát hiện khuyết tật. Khác với các phương pháp truyền thống bắt đầu tinh chỉnh với trọng số ImageNet, phương pháp của chúng tôi sử dụng các tính năng thích hợp để sản xuất hình ảnh, bắt nguồn từ quá trình đào tạo trước tự giám sát. Cách tiếp cận này có khả năng cho phép mô hình đồng hóa các tính năng khuyết tật cục bộ hiệu quả hơn vì nó tích hợp các biểu diễn trực quan đã học với các cơ chế phát hiện lỗi truyền thống, tận dụng các đại diện toàn cầu của các sản phẩm sản xuất có được trong giai đoạn tiền đào tạo. Do đó, hệ thống phát hiện khuyết tật cuối cùng dự kiến sẽ mạnh mẽ và đáng tin cậy hơn trong việc phát hiện lỗi, mang lại sự cải tiến đáng kể so với các phương pháp truyền thống.
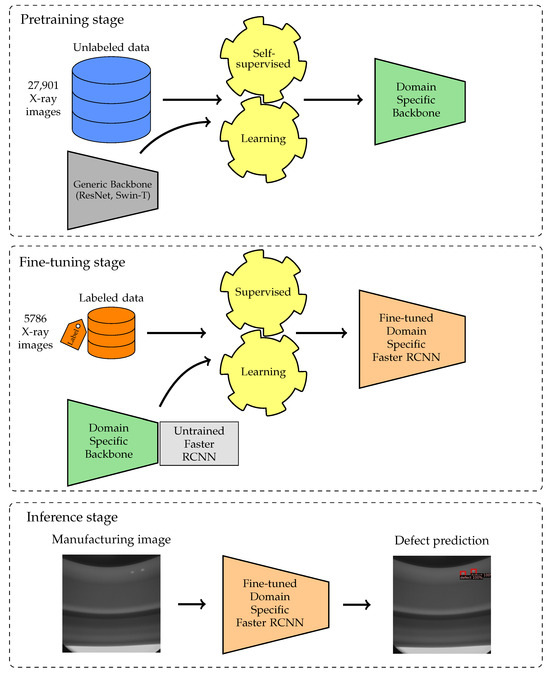
Hình 1 cho thấy tổng quan về phương pháp luận, bao gồm hai giai đoạn chính: tiền đào tạo và tinh chỉnh. Trong giai đoạn tiền đào tạo, xương sống của mô hình được đào tạo thông qua phương pháp học tập tự giám sát. Khóa đào tạo này trang bị cho mô hình khả năng trích xuất cụ thể các tính năng từ hình ảnh sản xuất tia X. Sau đó, xương sống được đào tạo được điều chỉnh thành một khung phát hiện đối tượng. Tại đây, nó trải qua một quá trình tinh chỉnh với bộ dữ liệu mục tiêu được chú thích, giúp tinh chỉnh thêm khả năng phát hiện lỗi của nó để sản xuất hình ảnh. Để đánh giá hiệu quả của phương pháp luận của chúng tôi, chúng tôi đã chọn hai phương pháp học tập tự giám sát: SimSiam [29] và SimMIM [44]. Mô tả chi tiết về các kỹ thuật này được cung cấp trong các tiểu mục sau.
Hình 1. Tổng quan về phương pháp: Quá trình này bao gồm hai giai đoạn, pretraining và fine-tunening. Ban đầu, chúng tôi sử dụng các kỹ thuật học tập tự giám sát SimSiam và SimMIM để đào tạo xương sống chung trên khối lượng lớn hình ảnh X-quang không được dán nhãn. Giai đoạn ban đầu này giúp mô hình nắm bắt các tính năng hình ảnh quan trọng liên quan đến lỗi sản xuất, loại bỏ nhu cầu chú thích dữ liệu. Sau đó, xương sống được đào tạo trước được tích hợp vào khung phát hiện đối tượng, nơi nó trải qua quá trình tinh chỉnh với tập dữ liệu mục tiêu được chú thích. Giai đoạn suy luận cuối cùng áp dụng mô hình tinh chỉnh để phát hiện chính xác các khiếm khuyết trong sản xuất hình ảnh, sử dụng các tính năng mạnh mẽ đã học được trong các giai đoạn trước để cải thiện độ chính xác và độ tin cậy.
3.2. SimSiam
Chúng tôi đã sử dụng SimSiam [29] để đào tạo trước một trình trích xuất tính năng được điều chỉnh đặc biệt để phân biệt giữa các tính năng có liên quan từ hình ảnh sản xuất. SimSiam được chọn vì sự đánh đổi tối ưu giữa sự đơn giản và hiệu quả trong các nhiệm vụ phân loại hình ảnh. Ưu điểm của nó nằm ở việc không yêu cầu kích thước lô lớn hoặc bộ mã hóa động lượng để đào tạo, giúp việc đào tạo trên nhiều GPU trở nên khả thi mà không đòi hỏi nguồn lực đáng kể.
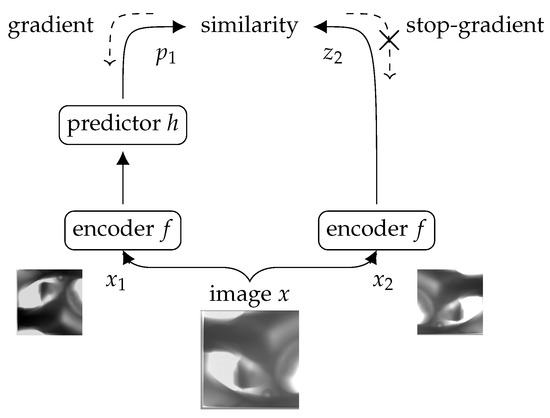
SimSiam là một phương pháp học tập tương phản sử dụng kiến trúc dựa trên mạng Xiêm. Phương pháp này đào tạo mô hình để tối đa hóa sự thỏa thuận giữa các chế độ xem tăng cường khác nhau của cùng một dữ liệu bằng cách sử dụng tổn thất tương phản trong không gian tiềm ẩn. Nó tạo ra hai lần tăng cường ngẫu nhiên, 𝑥1�1 và 𝑥2�2, từ một hình ảnh X sau đó được xử lý bởi một mạng mã hóa f. Bộ mã hóa f này, bao gồm một xương sống như ResNet50 [45] và đầu perceptron đa lớp chiếu (MLP), chia sẻ trọng lượng của nó trên các chế độ xem để trích xuất tính năng nhất quán. Ngoài ra, một MLP riêng biệt, ký hiệu là h, đóng vai trò là đầu dự đoán, chuyển đổi đầu ra của một chế độ xem để phù hợp với chế độ xem khác. Theo ký hiệu của bài báo gốc, các vectơ biến đổi và ban đầu được biểu diễn dưới dạng 𝑝1≜h(𝑓(𝑥1))�1≜ℎ(�(�1)) và 𝑧2≜𝑓(𝑥2)�2≜�(�2)Tương ứng. Theo cách đối xứng, mô hình cũng xử lý các phần tăng trưởng nghịch đảo, tạo ra 𝑧1≜𝑓(𝑥1)�1≜�(�1) và 𝑝2≜h(𝑓(𝑥2))�2≜ℎ(�(�2)). Sự đối xứng này trong chức năng mất mát giúp tăng cường đáng kể sự mạnh mẽ và hiệu quả học tập của mô hình. Mục tiêu cốt lõi của SimSiam là giảm thiểu sự tương đồng cosin tiêu cực giữa các cặp (𝑝1�1 và 𝑧2�2 và 𝑝2�2 và 𝑧1�1), do đó sắp xếp các biểu diễn này mặc dù các biến thể do tăng cường của chúng.
đâu ∥𝑝1∥2∥�1∥2 và ∥𝑝2∥2∥�2∥2 là các chỉ tiêu L2 của 𝑝1�1 và 𝑝2�2Tương ứng. Một yếu tố quan trọng của phương pháp SimSiam là hoạt động stop-gradient, đây là chìa khóa để ngăn chặn một giải pháp sụp đổ trong đó tất cả các đầu ra hội tụ vào cùng một vector. Thao tác này được áp dụng cho đầu ra của bộ mã hóa f, coi nó là hằng số trong một phần của khóa đào tạo. Kỹ thuật này giúp duy trì sự đa dạng trong các tính năng đã học, đảm bảo rằng mô hình không giảm thiểu tổn thất một cách tầm thường bằng cách hội tụ đến một đầu ra không đổi, như minh họa trong Hình 2. Dạng cuối cùng của hàm tổn thất được định nghĩa như sau:
Hình 2. Tổng quan về kiến trúc SimSiam [29]. Từ hình ảnh gốc, hai phiên bản tăng cường được xử lý bởi mạng Xiêm để trích xuất và căn chỉnh các tính năng, sử dụng hoạt động dốc dừng để ngăn chặn các giải pháp sụp đổ. Chiến lược này giảm thiểu sự tương đồng cosin tiêu cực, tăng cường nhận dạng tính năng nhất quán giữa các biến thể với học tập tương phản hiệu quả.
Mục tiêu là để mô hình tìm hiểu các biểu diễn bất biến đối với các phần tăng cường, đảm bảo mô hình mang lại kết quả đầu ra nhất quán cho các chế độ xem khác nhau của cùng một hình ảnh. Điều này đòi hỏi phải lựa chọn cẩn thận các phần bổ sung đủ bất biến để bỏ qua các biến thể tầm thường, nhưng không quá mức, vì vậy thông tin quan trọng cho các nhiệm vụ hạ nguồn không bị loại bỏ [46]. Đạt được sự cân bằng này cho phép mô hình xác định và làm nổi bật các tính năng có liên quan một cách hiệu quả. Trong bài báo gốc, các tác giả đã sử dụng một loạt các tăng cường, bao gồm hình học (chẳng hạn như cắt hình ảnh lên đến 20% và lật ngang), sửa đổi màu sắc (độ sáng, độ tương phản, độ bão hòa, màu sắc và thang độ xám) và làm mờ Gaussian. Chúng tôi đã làm theo cùng một chiến lược trong cách tiếp cận của chúng tôi.
3.3. SimMIM
Máy biến áp đã nổi lên như một nhà nước của nghệ thuật cho một loạt các nhiệm vụ liên quan đến tầm nhìn, chủ yếu là do khả năng đặc biệt của họ trong việc trích xuất tính năng và học tập biểu diễn [37]. Tiến bộ này đã truyền cảm hứng cho việc khám phá của chúng tôi vào ứng dụng của họ để phát hiện khuyết tật trong quy trình sản xuất.
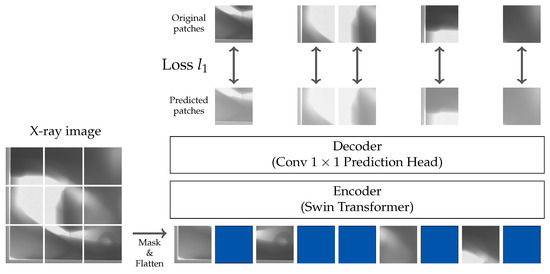
Hơn nữa, với mục đích tối đa hóa khả năng của Transformers, việc lựa chọn phương pháp tiền đào tạo là rất quan trọng [47]. Xem xét nhu cầu về các mô hình phát hiện khuyết tật để phát hiện chính xác các tính năng trên nhiều độ phân giải, chúng tôi đã chọn phương pháp SimMIM [44] cho giai đoạn tiền đào tạo về hình ảnh sản xuất tia X. Sự lựa chọn này được thông báo bởi khả năng tương thích của SimMIM với Máy biến áp tầm nhìn đa quy mô, điều này rất cần thiết để phân biệt tính năng hiệu quả ở các quy mô khác nhau. Áp dụng phương pháp mô hình hóa hình ảnh đeo mặt nạ, SimMIM nhằm mục đích có được các biểu diễn trực quan bằng cách tái tạo các bản vá hình ảnh được che giấu ngẫu nhiên. Cách tiếp cận này cho phép hiểu sâu hơn về bối cảnh thị giác cơ bản.
Cách tiếp cận SimMIM kết hợp chiến lược giải mã bộ mã hóa. Bộ mã hóa chịu trách nhiệm trích xuất các biểu diễn tính năng tiềm ẩn từ các phần không được che giấu của các bản vá hình ảnh. Bộ giải mã tái tạo lại các giá trị pixel của các bản vá lỗi. 𝑙1�1 Mất mát được sử dụng để đào tạo mô hình này. Quá trình này liên quan đến các bản đồ tính năng có độ phân giải được lấy mẫu xuống từ bộ mã hóa được ánh xạ trở lại bản đồ tính năng có độ phân giải ban đầu thông qua lớp tích chập 1 × 1. Các 𝑙1�1 Sau đó, chức năng mất được áp dụng cụ thể cho các pixel bị che bằng công thức sau:
ℒ=1Ω(𝑥𝑀)∥𝐲𝑀−𝐱𝑀∥1�=1�(��)∥��−��∥1
trong đó x và y đại diện cho hình ảnh đầu vào và các giá trị dự đoán, tương ứng, với M biểu thị các pixel được che và Ω� số lượng hình ảnh. Hình 3 cung cấp một biểu diễn sơ đồ của kiến trúc mô hình.
Hình 3. Tổng quan về kiến trúc SimMIM [44]. SimMIM dựa trên cơ chế giải mã bộ mã hóa được sử dụng để trích xuất tính năng và tái tạo các bản vá hình ảnh bị che giấu. Bộ mã hóa xử lý các phần không bị che khuất của hình ảnh, trong khi bộ giải mã nhằm mục đích tái tạo lại các khu vực bị che khuất. Nó được đào tạo bằng cách sử dụng một 𝑙1�1 Chức năng mất để ánh xạ các tính năng có độ phân giải lấy mẫu xuống ánh xạ trở lại độ phân giải ban đầu của chúng.
Khía cạnh quan trọng của SimMIM là quá trình tái tạo hiệu quả của nó, chứng minh rằng đầu dự đoán nhẹ có thể hoạt động tương đương, nếu không muốn nói là tốt hơn so với các bộ giải mã tái tạo phức tạp hơn [44]. Hiệu quả này không chỉ duy trì độ chính xác mà còn giảm đáng kể thời gian tiền đào tạo và nhu cầu tài nguyên tính toán.
Chiến lược mặt nạ trong SimMIM, rất quan trọng để tối đa hóa hiệu quả của nó, liên quan đến việc áp dụng mặt nạ ngẫu nhiên cho hình ảnh. SimMIM chứng minh rằng kích thước bản vá lớn hơn hoặc tỷ lệ che giấu cao hơn dẫn đến hiệu suất được cải thiện trong các tác vụ hạ nguồn [44]. Điều này được cho là do giảm mối tương quan giữa các pixel không bị che và bị che khi các khu vực hình ảnh lớn hơn được che lại, buộc người mẫu phải tìm hiểu thêm thông tin ngữ nghĩa thay vì sao chép các pixel có tương quan cao gần nhất. Ví dụ, trong phân loại ImageNet, SimMIM đạt được kết quả tối ưu với kích thước miếng vá mặt nạ 32 pixel và tỷ lệ mặt nạ 60% vì nó buộc mô hình phải suy ra các tính năng hình ảnh phức tạp hơn và ít rõ ràng hơn.
Một lợi thế đáng chú ý của chiến lược SimMIM so với các phương pháp tiếp cận như SimSiam là nó không yêu cầu tăng cường dữ liệu được lựa chọn cụ thể cho từng vấn đề. Đặc tính này đơn giản hóa việc áp dụng phương pháp trong các tình huống khác nhau, giảm nhu cầu về các chiến lược tăng cường tùy chỉnh và do đó tối ưu hóa quá trình đào tạo mô hình và thích ứng với các nhiệm vụ khác nhau.
4. Thực hiện và kết quả
Trong phần này, chúng tôi trình bày các thí nghiệm được thực hiện để đánh giá hiệu quả của các mô hình được đào tạo trước về hình ảnh X-quang của các sản phẩm sản xuất. Chúng tôi trình bày chi tiết các bộ dữ liệu cụ thể được sử dụng trong các thí nghiệm của chúng tôi và thảo luận về các phương pháp được áp dụng. Phần này cũng thảo luận về các kết quả thu được, cung cấp cái nhìn sâu sắc về ý nghĩa hiệu suất của các phương pháp tiền đào tạo khác nhau.
4.1. Đào tạo trước về hình ảnh X-quang
Chúng tôi đã sử dụng hai phương pháp tự giám sát nêu trên, SimSiam [35] và SimMIM [44], để thực hiện giai đoạn tiền đào tạo mô hình trên hình ảnh sản xuất tia X. Giả thuyết của chúng tôi là việc đào tạo trước tự giám sát trên một bộ dữ liệu lớn về hình ảnh tia X có thể cải thiện hiệu suất của các mô hình trong sản xuất các nhiệm vụ phát hiện lỗi hạ nguồn.
Đối với giai đoạn tiền đào tạo, một khối lượng hình ảnh đáng kể là điều cần thiết. Tuy nhiên, cách tiếp cận tự giám sát giúp loại bỏ sự cần thiết của chú thích, giúp thu thập một tập dữ liệu lớn không được gắn nhãn dễ dàng hơn. Trong các môi trường công nghiệp nơi hình ảnh không có chú thích có sẵn, cách tiếp cận này đặc biệt thuận lợi, phá vỡ quy trình tốn kém và tốn nhiều công sức để chú thích các lỗi theo cách thủ công. Sau đó, một phân tích chuyên sâu về các bộ dữ liệu được sử dụng trong nghiên cứu của chúng tôi được cung cấp trong Phần 4.2.
Để đánh giá tác động của pretraining đối với hình ảnh X-quang, chúng tôi đã đối chiếu các mô hình được tinh chỉnh từ ImageNet với các mô hình được tinh chỉnh sau khi đào tạo trước hình ảnh X-quang. Chúng tôi đã sử dụng hai giao thức đánh giá để so sánh: phân loại tuyến tính và tinh chỉnh.
Phân loại tuyến tính: Phương pháp đánh giá này là một giao thức được công nhận rộng rãi để đánh giá hiệu quả của các kỹ thuật học tập tự giám sát [28,29,35,48]. Theo cách tiếp cận này, mạng xương sống được đào tạo trước được giữ cố định (đóng băng) và đánh giá tập trung vào việc đào tạo một lớp được kết nối đầy đủ duy nhất được gắn vào đỉnh của xương sống. Lớp bổ sung này, kết hợp chức năng kích hoạt softmax, xử lý vectơ tính năng có nguồn gốc từ lớp tổng hợp trung bình toàn cầu của xương sống và nó được đào tạo trên tập dữ liệu đích. Mục tiêu chính của giao thức này là đánh giá và so sánh khả năng phân loại của các mạng xương sống khác nhau trong một cài đặt tiêu chuẩn, do đó cung cấp thông tin chi tiết về hiệu suất và khả năng thích ứng tương đối của chúng;
Tinh chỉnh: Trong giao thức này, các tính năng của xương sống được đào tạo trước được điều chỉnh cho các tác vụ hạ lưu cụ thể, chẳng hạn như phát hiện lỗi. Quá trình này liên quan đến việc sử dụng các trọng số được đào tạo trước của xương sống làm thiết lập ban đầu, sau đó được tinh chỉnh cho các kiến trúc tác vụ cụ thể như Faster R-CNN [19] và UNet [49] trên tập dữ liệu đích, nâng cao hiệu suất của chúng trong các ứng dụng chuyên biệt.
Tinh chỉnh thường vượt qua phân loại tuyến tính về hiệu suất, phần lớn là do việc sử dụng các kiến trúc phức tạp hơn và các ràng buộc vốn có liên quan đến việc sử dụng xương sống đóng băng trong phương pháp phân loại tuyến tính. Bằng cách phân tích đồng thời cả hai giao thức, chúng tôi đã tạo điều kiện đánh giá nhanh chóng nhưng toàn diện về các trình trích xuất tính năng khác nhau. Phân tích phương pháp kép này cung cấp một khuôn khổ đáng tin cậy và mạnh mẽ để đánh giá các mô hình, đặc biệt phù hợp với nhu cầu của các ứng dụng công nghiệp trong thế giới thực, nơi hiệu suất thực tế và khả năng thích ứng là tối quan trọng. Tuy nhiên, mục tiêu chính của nghiên cứu này là nâng cao hiệu quả của các hệ thống phát hiện lỗi sản xuất hiện có. Trong bối cảnh này, tinh chỉnh nổi lên như một số liệu quan trọng hơn do tác động trực tiếp của nó trong việc cải thiện khả năng phát hiện thực tế. Do đó, chúng tôi đã chọn tinh chỉnh làm giao thức chính để phát hiện lỗi sản xuất.
4.2. Trường hợp sử dụng
Trong các thí nghiệm sau, chúng tôi nhằm mục đích đánh giá hiệu quả của các phương pháp bằng cách sử dụng hai bộ dữ liệu chính.
4.2.1. Bộ dữ liệu công nghiệp
Bộ dữ liệu công nghiệp bao gồm các hình ảnh sản xuất tia X thu được từ dây chuyền sản xuất trong một công ty sản xuất. Dữ liệu thí nghiệm thu được bằng máy X-quang chụp hình ảnh của các sản phẩm sản xuất trên dây chuyền sản xuất. Những hình ảnh này được lưu trữ và sau đó được chú thích bởi một chuyên gia X-quang để sử dụng trong đào tạo mô hình.
Việc thu thập hình ảnh tia X được sử dụng trong nghiên cứu này phải tuân theo các giao thức độc quyền và bí mật theo yêu cầu của công ty sản xuất hợp tác. Điều quan trọng cần lưu ý là nghiên cứu của chúng tôi chỉ bắt đầu sau khi các hình ảnh đã được thu thập, chỉ tập trung vào phân tích dựa trên học sâu về những hình ảnh này. Chúng tôi không tham gia hoặc không có quyền truy cập vào quá trình thu thập hình ảnh. Làm nổi bật thực tế này là điều cần thiết để hiểu rõ trọng tâm nghiên cứu của chúng tôi, chỉ phân tích các hình ảnh được cung cấp.
Tập dữ liệu này được chia thành hai tập hợp con: một bộ dữ liệu tiền đào tạo mở rộng và một bộ dữ liệu mục tiêu nhỏ hơn, được chú thích để đánh giá và tinh chỉnh mô hình. Ban đầu, chúng tôi đã biên soạn một bộ đáng kể chứa 27.901 hình ảnh không được gắn nhãn, mà chúng tôi chỉ định là tập dữ liệu tiền đào tạo. Bộ dữ liệu này đóng vai trò là nền tảng cho giai đoạn tiền đào tạo, chủ yếu là do thiếu chú thích. Việc thu thập các hình ảnh không được gắn nhãn trong một môi trường công nghiệp thực tế là tương đối đơn giản. Sau đó, một bộ thứ hai được phát triển với các chú thích cấp độ hình ảnh và sự thật mặt đất, bao gồm 5786 hình ảnh. Bộ này nhỏ hơn bộ đầu tiên, chủ yếu là do chú thích hình ảnh tốn nhiều tài nguyên. Tuy nhiên, kích thước này được coi là phù hợp với mục đích của chúng tôi. Chúng tôi đã chỉ định tập hợp này làm tập dữ liệu đích, được sử dụng cả để đánh giá xương sống bằng giao thức phân loại tuyến tính và để tinh chỉnh mô hình đặc biệt để phát hiện lỗi sản xuất trong môi trường công nghiệp. Trong cả hai bộ dữ liệu, hình ảnh thang độ xám mô tả các góc nhìn khác nhau của cùng một sản phẩm, mỗi góc có kích thước từ 1024 × 1024 pixel. Trong tập dữ liệu đích, các chú thích sự thật mặt đất cho tất cả các lỗi được cung cấp dưới dạng hộp giới hạn, đảm bảo các điểm tham chiếu chính xác để phát hiện lỗi. Bộ dữ liệu đích chứa 19 loại khuyết tật được chú thích với kích thước, quy mô và cường độ đa dạng, thể hiện sự thay đổi đáng kể. Sau bước tiền xử lý, các khuyết tật được phân loại thành hai nhóm chính: nghiêm trọng và nhỏ. Như tên gọi của chúng, việc phát hiện chính xác các khuyết tật nghiêm trọng là rất cần thiết do các tác động an toàn tiềm ẩn. Phát hiện các khuyết tật nhỏ cũng rất quan trọng, mặc dù mức độ nghiêm trọng của chúng tương đối thấp hơn, khiến việc xác định chúng trở nên quan trọng không kém nhưng ít quan trọng hơn đối với các mối quan tâm về an toàn. Phân phối khuyết tật bao gồm 7 loại khuyết tật nghiêm trọng và 12 loại khuyết tật nhỏ, đặt ra một vấn đề phát hiện khuyết tật đầy thách thức với mục tiêu kép: xác định vị trí khuyết tật trên sản phẩm và phân loại chúng thành một trong hai loại. Liên quan đến phân phối tập dữ liệu, sự mất cân bằng lớp đáng kể là rõ ràng, với 1784 mẫu cho các khuyết tật nghiêm trọng và 4002 mẫu cho các khuyết tật nhỏ. Việc phân vùng tập dữ liệu mục tiêu thành các bộ đào tạo và kiểm tra trong khi vẫn duy trì tỷ lệ lớp được trình bày chi tiết trong Bảng 1.
Bảng 1. Phân phối hình ảnh cho các khiếm khuyết nghiêm trọng và nhỏ trong tập dữ liệu đích.
4.2.2. Bộ dữ liệu GDXray
Vì tập dữ liệu được đề cập ở trên là riêng tư, chúng tôi cũng đã xem xét đánh giá các phương pháp trên tập dữ liệu chuẩn. GDXray [20] là một bộ dữ liệu có sẵn công khai về hình ảnh X-quang. Nó chứa 19.407 hình ảnh được tổ chức thành năm nhóm: đúc, mối hàn, hành lý, vật thể tự nhiên và cài đặt, mỗi nhóm có nhiều chuỗi. Khi chúng tôi xử lý việc phát hiện lỗi sản xuất, chúng tôi tập trung vào nhóm đúc, liên quan đến sản xuất và bao gồm 2727 hình ảnh tia X từ 67 series chủ yếu có các bộ phận ô tô như bánh xe nhôm và đốt ngón tay. Những hình ảnh này được chú thích bằng các hộp giới hạn, tương tự như trong tập dữ liệu đầu tiên, cung cấp một điểm chuẩn để đánh giá các phương pháp của chúng tôi trong phát hiện lỗi sản xuất. Tuy nhiên, đáng chú ý là, không giống như bộ dữ liệu mục tiêu công nghiệp của chúng tôi, GDXray không phân loại lỗi thành các loại khác nhau. Ngoài ra, xem xét rằng các tài liệu hiện có sử dụng GDXray chủ yếu giải quyết vấn đề phát hiện lỗi hơn là phân loại, chúng tôi đã chọn không thực hiện đánh giá phân loại tuyến tính cho tập dữ liệu này. Do đó, phân tích của chúng tôi về bộ dữ liệu GDXray bị giới hạn trong việc đánh giá tinh chỉnh.
4.3. Kết quả
Trong phần này, chúng tôi trình bày một số thí nghiệm để đánh giá những lợi thế của việc áp dụng một giai đoạn tiền đào tạo cụ thể cho hình ảnh sản xuất tia X.
4.4. Phân loại tuyến tính
Ban đầu, chúng tôi đào tạo một mô hình xương sống sử dụng cả SimSiam và SimMIM. Chúng tôi đã tuân theo sơ đồ mặc định từ các giấy tờ gốc trong cả hai trường hợp và chúng tôi đã đào tạo các mô hình cho 100 kỷ nguyên. Sau đó, chúng tôi thực hiện giao thức đánh giá tiêu chuẩn cho các mô hình được đào tạo trước; Chúng tôi đã thêm một lớp tuyến tính ở trên cùng của mô hình, với phần còn lại của các lớp xương sống bị đóng băng. Chúng tôi đã đào tạo mô hình phân loại này trên tập dữ liệu đích với các lỗi nghiêm trọng và nhỏ. Chúng tôi đã thiết lập một đường cơ sở bằng cách sử dụng một mô hình với các trọng số được đào tạo trước ImageNet. Đối với SimSiam, chúng tôi đã sử dụng ResNet50 [45] làm trình trích xuất tính năng, tạo ra vectơ tính năng 2048 chiều cho lớp phân loại. Ngược lại, đối với SimMIM, chúng tôi đã sử dụng Swin Transformer gốc [38] được cấu hình với kích thước cửa sổ 12 pixel. Vectơ tính năng trong trường hợp của Swin Transformer là 1024 chiều. Kết quả của phân loại tuyến tính này trên tập dữ liệu mục tiêu của chúng tôi được trình bày chi tiết trong Bảng 2.
Bảng 2. Kết quả phân loại tuyến tính trên bộ dữ liệu mục tiêu công nghiệp cho cả xương sống ResNet và Swin-T. ImageNet đề cập đến mô hình được đào tạo trước với tập dữ liệu ImageNet tiêu chuẩn, X-quang SimSiam biểu thị trọng lượng thu được từ phương pháp SimSiam được đào tạo trước bằng hình ảnh tia X và SimMIM tia X cho biết trọng lượng bắt nguồn từ phương pháp SimMIM trong các điều kiện tương tự.
Bảng 2 so sánh hiệu suất của các kiến trúc xương sống khác nhau bằng cách sử dụng trọng lượng ImageNet so với trọng lượng thu được thông qua các phương pháp huấn luyện trước tự giám sát với hình ảnh X-quang. Từ kết quả, chúng tôi quan sát thấy rằng, đối với xương sống ResNet, phương pháp đào tạo trước SimSiam vượt trội hơn phương pháp được giám sát về cả Độ chính xác trung bình (AP) và độ chính xác. Cụ thể, SimSiam đạt được AP cao hơn 75,9 so với 72,5 và độ chính xác được cải thiện là 71,2 so với 68,4 được thấy bằng phương pháp được giám sát. Tuy nhiên, đối với xương sống Swin-T, phương pháp giám sát thể hiện hiệu suất vượt trội với AP cao 87,9 và độ chính xác 82,2.
Tuy nhiên, điều quan trọng cần lưu ý là kết quả từ việc đào tạo trước với SimMIM không thỏa đáng. Cách tiếp cận này dường như làm nổi bật các đặc điểm toàn cầu của hình ảnh hơn là các đặc điểm liên quan hơn liên quan đến các khiếm khuyết. Vì các khuyết tật thường khá nhỏ so với độ phân giải hình ảnh tổng thể, các tính năng thích hợp với các khuyết tật này có xu hướng bị lu mờ bởi các đặc điểm cấu trúc nổi bật hơn của sản phẩm được sản xuất. Xu hướng này có xu hướng làm giảm hiệu quả trong việc phát hiện khuyết tật cụ thể trừ khi tinh chỉnh được áp dụng cho xương sống để dạy chính xác các đặc điểm của khuyết tật. Trong những trường hợp như vậy, mô hình tìm hiểu cả các đặc điểm cấu trúc của sản phẩm và các đặc tính cục bộ của các khuyết tật, trái ngược với các giá trị AP và độ chính xác thấp hơn được quan sát thấy trong quá trình đào tạo trước SimMIM mà không cần tinh chỉnh mục tiêu như vậy. Tuy nhiên, như chúng tôi đã giải thích trong Phần 4.1, tinh chỉnh là giao thức tối ưu để phát hiện lỗi sản xuất.
4.5. Tinh chỉnh bộ dữ liệu sản xuất
Sau giai đoạn phân loại tuyến tính, nghiên cứu của chúng tôi tiến tới giai đoạn tinh chỉnh toàn diện hơn và chúng tôi đã áp dụng mô hình R-CNN nhanh hơn để phát hiện lỗi trên hai bộ dữ liệu riêng biệt: bộ dữ liệu mục tiêu công nghiệp của chúng tôi và bộ dữ liệu GDXray chuẩn. Giai đoạn này được thiết kế để cung cấp cái nhìn sâu sắc hơn về khả năng ứng dụng và hiệu quả thực tế của các mô hình được đào tạo trước trong bối cảnh công nghiệp thực tế và đa dạng.
Trong giai đoạn đầu của giai đoạn tinh chỉnh này, chúng tôi đã đào tạo mô hình R-CNN nhanh hơn trên tập dữ liệu mục tiêu công nghiệp bằng cách sử dụng ba bộ trọng lượng bắt đầu: những trọng lượng thu được từ quá trình đào tạo trước tia X bằng cả phương pháp SimSiam và SimMIM và những trọng lượng được khởi tạo bằng ImageNet. Chiến lược này được sử dụng để đánh giá hiệu quả của các mô hình trong việc xử lý các nhiệm vụ phát hiện khuyết tật phức tạp, trong thế giới thực trong ngành sản xuất. Kết quả, như được nêu chi tiết trong Bảng 3, minh họa hiệu suất vượt trội của các phương pháp đào tạo trước SimSiam và SimMIM so với phương pháp giám sát thông thường, đặc biệt là trong việc xác định các khiếm khuyết nghiêm trọng.
Bảng 3. Tinh chỉnh kết quả phát hiện khuyết tật cho bộ dữ liệu sản xuất. Hiệu suất tinh chỉnh của mô hình R-CNN nhanh hơn được đánh giá trên hai bộ dữ liệu, bộ dữ liệu mục tiêu công nghiệp và bộ dữ liệu GDXray, sử dụng xương sống ResNet và Swin-T với trọng lượng ban đầu khác nhau (ImageNet, X-ray SimSiam và X-ray SimMIM). Độ chính xác trung bình trung bình (mAP) được báo cáo cho tập dữ liệu công nghiệp và Độ chính xác trung bình (AP) cho tập dữ liệu GDXray, được chỉ định là (m) AP. Ký hiệu này được sử dụng vì tập dữ liệu công nghiệp chứa hai loại lỗi, trong khi tập dữ liệu GDXray không phân loại lỗi. Ngoài ra, AP-Critical được báo cáo cho tập dữ liệu công nghiệp, cho biết độ chính xác của mô hình trong việc phát hiện các khuyết tật nghiêm trọng.
Sau đó, đánh giá của chúng tôi đã được mở rộng sang tập dữ liệu GDXray, sao chép quá trình tinh chỉnh được thực hiện với tập dữ liệu mục tiêu công nghiệp nhưng lần này áp dụng nó vào bộ dữ liệu đào tạo GDXray. Bước này nhằm kiểm tra tính khái quát và tính mạnh mẽ của mô hình trong một bối cảnh khác biệt rõ rệt. Bộ dữ liệu GDXray, với các đặc điểm và thách thức độc đáo, đã cung cấp một nền tảng lý tưởng để đánh giá các mô hình, được đào tạo trước trên tập dữ liệu không nhãn công nghiệp của chúng tôi, có thể thích ứng và hoạt động tốt như thế nào trong một loạt các kịch bản công nghiệp.
Các kết quả kết hợp từ cả hai bộ dữ liệu được trình bày trong Bảng 3, bao gồm các chỉ số hiệu suất trên cả tập dữ liệu mục tiêu công nghiệp và tập dữ liệu GDXray. Những kết quả này nhấn mạnh tính linh hoạt và hiệu quả của các phương pháp tiền đào tạo SimSiam và SimMIM trong việc nâng cao hiệu suất của các mô hình phát hiện khuyết tật trên các bộ dữ liệu hình ảnh tia X đa dạng.
Đối với bộ dữ liệu công nghiệp, hiệu suất của mô hình được định lượng bằng Độ chính xác trung bình trung bình (mAP) và AP-Critical, sau này cho thấy độ chính xác trong việc phát hiện các khuyết tật nghiêm trọng. Kết quả cho thấy cả hai phương pháp pretraining SimSiam và SimMIM đều nâng cao hiệu suất so với khởi tạo ImageNet truyền thống. Đáng chú ý, đối với xương sống ResNet, phương pháp SimSiam mang lại mAP cao hơn một chút là 89,6 và AP-Critical là 94,8 so với trọng số ImageNet. Tương tự, xương sống Swin-T được đào tạo trước với SimMIM phù hợp với mAP cao nhất là 91.3 đạt được bởi phiên bản ImageNet và thậm chí còn vượt qua nó trong AP-Critical với số điểm 95.5.
Trên tập dữ liệu GDXray, quá trình tinh chỉnh đã chứng minh khả năng khái quát hóa của các mô hình được đào tạo trước. Mô hình ResNet được đào tạo trước SimSiam đạt được AP là 96.0, vượt trội hơn một chút so với phiên bản dựa trên ImageNet từ Ferguson et al. [4]. Đối với xương sống Swin-T, phương pháp huấn luyện trước SimMIM dẫn đến AP là 94,6, cho thấy hiệu suất được cải thiện so với trọng số ImageNet. Những phát hiện này từ cả hai bộ dữ liệu nhấn mạnh hiệu quả của các kỹ thuật đào tạo trước SimSiam và SimMIM, không chỉ trong việc cải thiện hiệu suất mô hình trong bối cảnh cụ thể của phát hiện lỗi công nghiệp mà còn khái quát hóa tốt cho phổ rộng hơn của các kịch bản hình ảnh X-quang.
4.6. Kết quả định tính
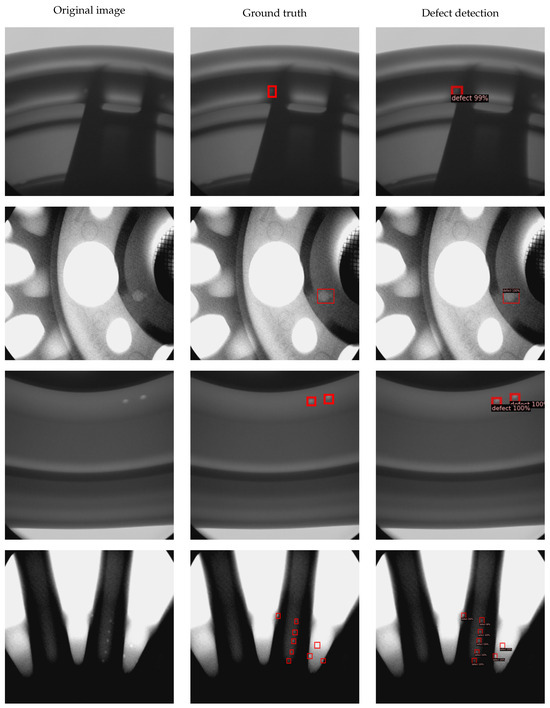
Trong tiểu mục này, chúng tôi trình bày kết quả thử nghiệm thông qua các hình ảnh trực quan làm nổi bật hiệu suất của mô hình phát hiện lỗi của chúng tôi. Tuy nhiên, do lo ngại về tính bảo mật, chúng tôi không thể hiển thị hình ảnh từ tập dữ liệu công nghiệp trong hình ảnh trực quan của chúng tôi. Thay vào đó, chúng tôi tập trung vào bộ dữ liệu GDXray để chứng minh hiệu suất của mô hình phát hiện lỗi của chúng tôi. Cụ thể, chúng tôi nhấn mạnh hiệu quả của xương sống ResNet được đào tạo trước bằng hình ảnh X-quang bằng cách sử dụng phương pháp SimSiam. Thông qua hình ảnh trực quan trong Hình 4, chúng tôi mong muốn cung cấp cái nhìn sâu sắc về ứng dụng thực tế và hiệu quả của mô hình của chúng tôi trong việc xác định các khiếm khuyết trong các tình huống công nghiệp.
Hình 4. Kết quả phát hiện lỗi trên tập dữ liệu GDXray. Hình này minh họa hình ảnh tia X ban đầu, chú thích sự thật mặt đất và dự đoán của mô hình.
5. Thảo luận
Những thí nghiệm này đã làm sáng tỏ hiệu quả của các phương pháp tiền đào tạo sử dụng hình ảnh X-quang, đặc biệt là trong bối cảnh phát hiện các khiếm khuyết trong sản xuất sản phẩm. Các thí nghiệm của chúng tôi cho thấy các mô hình được đào tạo trước bằng hình ảnh tia X thường vượt trội hơn các mô hình được đào tạo trước với ImageNet trong việc phân biệt các tính năng liên quan để phát hiện lỗi. Tính ưu việt này của pretraining theo miền cụ thể làm nổi bật tầm quan trọng của việc sắp xếp giai đoạn tiền đào tạo với các đặc điểm độc đáo của hình ảnh nhiệm vụ cụ thể.
Khi so sánh các xương sống khác nhau, các mô hình Máy biến áp Swin thể hiện hiệu suất vượt trội so với CNN khi dữ liệu lớn, được dán nhãn có sẵn [37]. Tuy nhiên, kịch bản khác với tập dữ liệu GDXray, có ít hình ảnh được gắn nhãn hơn; ở đây, xương sống CNN mang lại kết quả tốt hơn. Điều này cho thấy rằng, trong khi Transformers hoạt động tốt hơn trong môi trường giàu dữ liệu, CNN có thể hiệu quả hơn với dữ liệu hạn chế.
Một khía cạnh quan trọng trong nghiên cứu của chúng tôi là sự cải thiện rõ rệt trong việc phát hiện các khuyết tật nghiêm trọng sau khi đào tạo trước bằng hình ảnh X-quang. Cải tiến này đặc biệt thích hợp trong các cơ sở công nghiệp, nơi xác định chính xác các khiếm khuyết như vậy là rất quan trọng đối với sự an toàn và độ tin cậy. Sự tăng cường này trong việc phát hiện khuyết tật, đặc biệt là đối với các khuyết tật nghiêm trọng, có thể có ý nghĩa đáng kể đối với các ứng dụng công nghiệp. Hơn nữa, việc đào tạo trước về hình ảnh tia X đã chứng minh kết quả được cải thiện ngay cả với bộ dữ liệu GDXray nhỏ hơn, cho thấy khả năng thích ứng của các mô hình với các khối lượng dữ liệu khác nhau. Khả năng thích ứng này là một đặc điểm quan trọng để triển khai thực tế, nơi tính khả dụng của dữ liệu có thể thay đổi.
Mặc dù hệ thống của chúng tôi chưa được triển khai trong môi trường sản xuất thực tế, nhưng những phát hiện của chúng tôi cho thấy rằng nó hứa hẹn cho các ứng dụng trong tương lai. Thời gian thực hiện khoảng 0,126 giây cho mỗi hình ảnh định vị phương pháp của chúng tôi nằm trong giới hạn hoạt động được đặt ra bởi các tiêu chuẩn ngành, cho phép tối đa 1 giây để phân tích hình ảnh. Chỉ số hiệu suất này cho thấy khả năng tồn tại của phương pháp tích hợp dây chuyền sản xuất của chúng tôi. Nó nhấn mạnh tiềm năng triển khai trong thế giới thực, do đó nâng cao tính khả thi của việc sử dụng học sâu để phát hiện các lỗi trong cài đặt sản xuất.
6. Kết luận
Nghiên cứu này góp phần vào những nỗ lực không ngừng trong việc tăng cường phát hiện khuyết tật trong sản xuất các sản phẩm sử dụng hình ảnh tia X. Các thí nghiệm và phân tích toàn diện của chúng tôi cho thấy một số phát hiện chính nhấn mạnh tính hiệu quả và khả năng áp dụng thực tế của phương pháp được đề xuất của chúng tôi trong các thiết lập công nghiệp. Nghiên cứu của chúng tôi kết luận rằng các mô hình được đào tạo trước về hình ảnh tia X luôn hoạt động tốt hơn những mô hình được đào tạo trước với trọng lượng ImageNet. Phát hiện này rất quan trọng vì nó nhấn mạnh tầm quan trọng của pretraining miền cụ thể trong việc tăng cường khả năng của mô hình để phân biệt các tính năng liên quan để phát hiện lỗi. Bằng cách căn chỉnh giai đoạn tiền đào tạo với các đặc điểm độc đáo của hình ảnh theo nhiệm vụ cụ thể, chúng tôi đã đạt được khả năng phát hiện vượt trội so với các khả năng đạt được với các mô hình được đào tạo trước trên các hình ảnh tổng quát hơn. Hơn nữa, việc so sánh các kiến trúc xương sống khác nhau cho thấy các xu hướng có giá trị. Chúng tôi quan sát thấy rằng, trong các kịch bản có dữ liệu được gắn nhãn phong phú, các mô hình Swin Transformer hoạt động tốt hơn CNN truyền thống, trong khi xương sống CNN hiệu quả hơn trong các bộ dữ liệu có ít hình ảnh được gắn nhãn hơn. Điều này ngụ ý rằng một mô hình tối ưu có thể được chọn tùy thuộc vào số lượng dữ liệu có sẵn và các yêu cầu cụ thể của nhiệm vụ. Đặc biệt đáng chú ý là sự cải thiện trong việc phát hiện các khuyết tật nghiêm trọng, một mối quan tâm quan trọng trong các thiết lập công nghiệp, đạt được thông qua việc đào tạo trước về hình ảnh X-quang. Trong bối cảnh công nghiệp, nơi việc xác định chính xác các khiếm khuyết như vậy là rất quan trọng để đảm bảo an toàn và duy trì các tiêu chuẩn chất lượng cao, những tiến bộ được hiển thị có thể góp phần đáng kể vào việc giảm rủi ro và nâng cao độ tin cậy.
Tóm lại, nghiên cứu này giới thiệu một phương pháp thúc đẩy đào tạo trước theo miền cụ thể với hình ảnh tia X để tăng cường phát hiện khuyết tật trong sản xuất sản phẩm. Đóng góp chính của chúng tôi nằm ở việc phát triển và áp dụng phương pháp này, trong đó nêu bật những lợi thế của việc đào tạo trước tùy chỉnh và lựa chọn chiến lược của kiến trúc xương sống phù hợp với chi tiết cụ thể của dữ liệu. Phương pháp của chúng tôi đã cải thiện đáng kể độ chính xác trong việc phát hiện các khuyết tật nghiêm trọng, dẫn đến sự phát triển của một khung phát hiện mạnh mẽ hơn. Tiến bộ này không chỉ thúc đẩy biên giới của công nghệ phát hiện khuyết tật mà còn cung cấp những hiểu biết có giá trị cho việc thực hiện các mô hình này trong môi trường công nghiệp. Việc thực hiện như vậy có khả năng nâng cao hiệu quả của các biện pháp kiểm soát chất lượng, do đó làm tăng độ an toàn và độ tin cậy của sản phẩm. Hơn nữa, việc áp dụng các hệ thống phát hiện nâng cao này có thể dẫn đến giảm đáng kể thời gian ngừng hoạt động và chi phí bảo trì, tối ưu hóa quy trình sản xuất và tăng hiệu quả công nghiệp tổng thể. Bằng cách nâng cao chất lượng sản phẩm và giảm thiểu tỷ lệ thất bại, chiến lược của chúng tôi hỗ trợ duy trì danh tiếng của các đơn vị sản xuất và nâng cao niềm tin của người tiêu dùng.
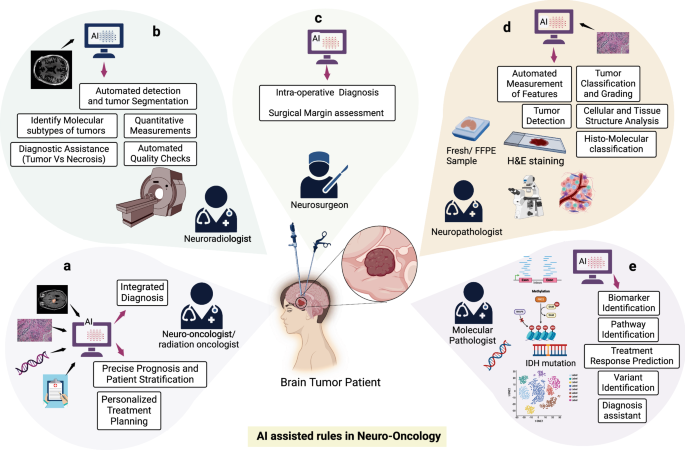
Trí tuệ nhân tạo trong ung thư thần kinh: những tiến bộ và thách thức trong chẩn đoán, tiên lượng và điều trị chính xác khối u não
434
Trí tuệ nhân tạo trong ung thư thần kinh: những tiến bộ và thách thức trong chẩn đoán, tiên lượng và điều trị chính xác khối u não
Tóm tắt
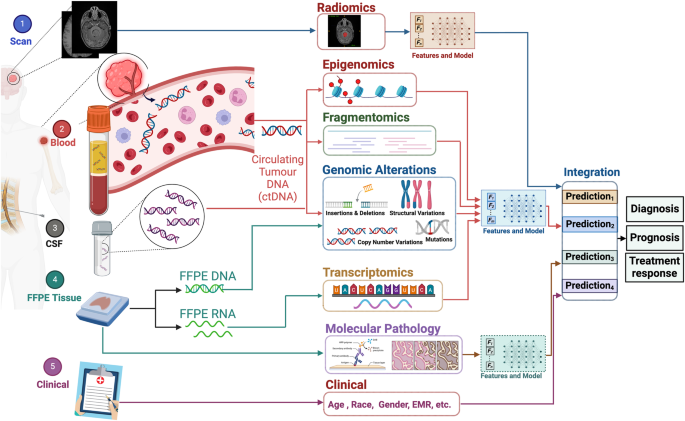
Đánh giá này đi sâu vào những tiến bộ gần đây nhất trong việc áp dụng trí tuệ nhân tạo (AI) trong ung thư thần kinh, đặc biệt nhấn mạnh công việc về u thần kinh đệm, một loại khối u não đại diện cho một vấn đề sức khỏe toàn cầu quan trọng. AI đã mang lại những đổi mới mang tính biến đổi để quản lý khối u não, sử dụng các công cụ hình ảnh, mô bệnh học và bộ gen để phát hiện, phân loại, dự đoán kết quả và lập kế hoạch điều trị hiệu quả. Đánh giá ảnh hưởng của nó trên tất cả các khía cạnh của quản lý khối u não ác tính – chẩn đoán, tiên lượng và điều trị – các mô hình AI vượt trội hơn các đánh giá của con người về độ chính xác và độ đặc hiệu. Khả năng phân biệt các khía cạnh phân tử từ hình ảnh có thể làm giảm sự phụ thuộc vào chẩn đoán xâm lấn và có thể đẩy nhanh thời gian chẩn đoán phân tử. Bài đánh giá bao gồm các kỹ thuật AI, từ học máy cổ điển đến học sâu, làm nổi bật các ứng dụng và thách thức hiện tại. Các hướng đi đầy hứa hẹn cho nghiên cứu trong tương lai bao gồm tích hợp dữ liệu đa phương thức, AI tạo ra, các mô hình ngôn ngữ y tế lớn, mô tả và mô tả khối u chính xác, và giải quyết sự chênh lệch về chủng tộc và giới tính. Các chiến lược điều trị cá nhân hóa thích ứng cũng được nhấn mạnh để tối ưu hóa kết quả lâm sàng. Ý nghĩa đạo đức, pháp lý và xã hội được thảo luận, ủng hộ tính minh bạch và công bằng trong tích hợp AI cho ung thư thần kinh và cung cấp sự hiểu biết toàn diện về tác động biến đổi của nó đối với chăm sóc bệnh nhân.
19 Tháng Ba 2024
Giới thiệu
Các khối u hệ thần kinh trung ương (CNS), dù là nguyên phát hay thứ phát, đều có tác động đáng kể đến sức khỏe toàn cầu, chiếm hơn 250.000 trường hợp được báo cáo hàng năm, đánh dấu chúng là mối quan tâm toàn cầu đáng kể1,2. Năm 2022, ước tính có khoảng 26.670 khối u ác tính và 66.806 khối u thần kinh trung ương không ác tính được chẩn đoán trong dân số Hoa Kỳ3. Đáng chú ý, u nguyên bào thần kinh đệm, một loại khối u não phát triển nhanh, hung dữ và ác tính, nổi lên như một đóng góp chính cho tỷ lệ mắc bệnh và tử vong ở các khối u não trưởng thành, thể hiện tỷ lệ sống sót sau 5 năm đáng lo ngại 6,9% và góp phần gây ra 10.000 ca tử vong hàng năm ở Mỹ4,5. Những con số này làm nổi bật những thiếu sót hiện tại trong điều trị khối u não.
Mặc dù có nhiều thử nghiệm lâm sàng và nhiều thập kỷ nghiên cứu, các khối u não không thể chữa khỏi với tiên lượng nghiệt ngã vẫn tồn tại, chẳng hạn như u thần kinh đệm đường giữa lan tỏa (DMG) thấy ở trẻ em và u nguyên bào thần kinh đệm ở người lớn6. Sự khẩn cấp này nhấn mạnh sự cần thiết của một phương pháp điều trị cá nhân hóa, có thể mang lại khả năng chữa khỏi cao nhất trong khi giảm thiểu độc tính tiềm ẩn cho bệnh nhân. Tuy nhiên, việc phát triển các chiến lược cá nhân hóa phải đối mặt với những trở ngại do khó khăn trong việc khái quát hóa các phương pháp tiếp cận có nguồn gốc từ dữ liệu có nguồn gốc từ một tổ chức đơn lẻ hoặc một tập đoàn hạn chế của các tổ chức và hạn chế quyền truy cập vào các công nghệ tiên tiến và thử nghiệm lâm sàng, chủ yếu tập trung ở các trung tâm chuyên ngành7. Điều này trở thành một mối quan tâm quan trọng, đặc biệt là khi suy ngẫm về các phân nhánh đạo đức liên quan đến việc phát triển các phương pháp tiếp cận dựa trên dữ liệu thiếu đại diện trên các nhân khẩu học đa dạng. Đáng báo động, những người bị u nguyên bào thần kinh đệm từ các nền kinh tế xã hội thấp hơn ít có khả năng trải qua xét nghiệm O6-Methylguanine-DNA-methyltransferase (MGMT)8. Sự vắng mặt của xét nghiệm MGMT có thể làm sai lệch dự đoán và góp phần chẩn đoán giai đoạn cuối với các khối u lớn hơn và khó khăn hơn. Hơn nữa, nhân khẩu học này ít được cung cấp với sự kết hợp của các phương thức điều trị đa dạng, dẫn đến tỷ lệ sống sót thấp hơn9.
Đối với một bệnh nhân bị nghi ngờ chứa u não, đánh giá thường bắt đầu bằng khám sức khỏe và hình ảnh thần kinh, sau đó là sinh thiết hoặc cắt bỏ khối u trong trường hợp khả thi và phân tích mô học và phân tử tiếp theo của mô chiết xuất được thực hiện thông qua bệnh lý. Nếu thấy cần thiết, cũng có thể thực hiện đánh giá dấu ấn sinh học trong huyết thanh hoặc dịch não tủy (CSF)10. Sau những đánh giá này, nhóm lâm sàng phải quyết định liệu pháp tối ưu, xem xét tiêu chuẩn chăm sóc, các thử nghiệm lâm sàng đang diễn ra, bệnh đi kèm của bệnh nhân và nguy cơ độc tính. Đáp ứng điều trị được theo dõi theo chiều dọc thông qua MRI nối tiếp và, đôi khi, các dấu ấn sinh học máu hoặc dịch não tủy khác11. Các quyết định liên quan đến điều trị khối u não thường liên quan đến các cuộc họp đa ngành giữa các bác sĩ ung thư thần kinh, bác sĩ phẫu thuật thần kinh, bác sĩ X quang thần kinh, nhà nghiên cứu bệnh học phân tử và nhà thần kinh học, nhấn mạnh sự phức tạp của các quyết định này12 (Hình. 1).
Hình 1: Quản lý khối u não đa ngành do AI trao quyền.
AI tăng cường khả năng của các bác sĩ ung thư thần kinh / bác sĩ ung thư bức xạ bằng cách cho phép chẩn đoán tích hợp, cung cấp những hiểu biết sâu sắc hơn về bệnh, tạo điều kiện tiên lượng chính xác bằng cách dự đoán kết quả và hỗ trợ phân tầng bệnh nhân để điều chỉnh kế hoạch điều trị theo nhu cầu cá nhân. b AI hỗ trợ các bác sĩ X quang thần kinh bằng cách tận dụng hình ảnh MRI để phát hiện tự động và phân đoạn khối u, xác định các phân nhóm phân tử của khối u, cung cấp các phép đo định lượng và cung cấp hỗ trợ chẩn đoán để phân biệt khối u với các vùng hoại tử, đồng thời đảm bảo kiểm tra chất lượng tự động. c AI hỗ trợ các bác sĩ phẫu thuật thần kinh trong quá trình phẫu thuật, góp phần đánh giá biên độ phẫu thuật và cung cấp thông tin và hướng dẫn chẩn đoán theo thời gian thực, nâng cao độ chính xác của phẫu thuật và kết quả của bệnh nhân. d AI hỗ trợ các nhà thần kinh học trong việc phân tích các mẫu mới / FFPE, cung cấp phép đo tự động các tính năng, hỗ trợ phân loại và phân loại khối u, cải thiện phát hiện khối u và phân tích toàn diện cấu trúc tế bào và mô thông qua phân loại mô phân tử. e Xử lý dữ liệu đột biến, thông tin tế bào đơn, mẫu methyl hóa, trình tự RNA, v.v., AI trao quyền cho các nhà nghiên cứu bệnh học phân tử bằng cách hỗ trợ xác định dấu ấn sinh học, xác định con đường, dự đoán đáp ứng điều trị, xác định biến thể và đóng vai trò trợ lý chẩn đoán, hợp lý hóa quy trình phân tích phân tử phức tạp (Được tạo bằng BioRender.com).
Tuy nhiên, các bước này trong quản lý bệnh có nhiều thách thức và sai sót có thể dẫn đến tỷ lệ mắc bệnh và tử vong của bệnh nhân13. Những thách thức bao gồm nhu cầu chẩn đoán và dàn dựng bệnh chính xác để hướng dẫn các quyết định lâm sàng, theo dõi liên tục tiến triển bệnh sau điều trị, có thể phức tạp bởi các tín hiệu từ mô thần kinh lân cận và ý nghĩa ngày càng tăng của việc xác định các mẫu kiểu gen14. Những mẫu kiểu gen này có tác động đáng kể đến hành vi của khối u và kết quả lâm sàng15. Cuối cùng, những thách thức trong việc quản lý khối u não phát sinh từ nhiều yếu tố khác nhau, bao gồm sự phức tạp của não, khả năng tiếp cận hạn chế đối với các thủ tục hình ảnh và sinh thiết chính xác, tính không đồng nhất vốn có của sinh học khối u, tỷ lệ tiến triển thay đổi, sự thay đổi cá nhân trong tính nhạy cảm với điều trị và thiếu tương đối các dấu ấn sinh học đáng tin cậy dự đoán tiên lượng1,16,17. Sự nhạy cảm của mô thần kinh với các phương thức điều trị tiêu chuẩn, bao gồm phẫu thuật, xạ trị và hóa trị, làm phức tạp thêm việc chăm sóc của họ18.
Trí tuệ nhân tạo (AI) hứa hẹn là một công cụ biến đổi trong ung thư thần kinh, hiện đang giải quyết các thách thức trong các giai đoạn quản lý lâm sàng khác nhau. Trong quản lý khối u não, AI thể hiện tiềm năng của nó thông qua chẩn đoán, tiên lượng và lập kế hoạch điều trị bằng cách tăng tốc và tăng cường hình ảnh MRI19, phát hiện bất thường, tối ưu hóa quy trình làm việc, cung cấp các phép đo chính xác, phân tích dữ liệu hình ảnh y tế rộng rãi và xác định các mẫu không dễ nhận ra đối với người quan sát20. Nó đã nâng cao đáng kể lĩnh vực này bằng cách cung cấp phân tích hình ảnh chi tiết để chẩn đoán, phân loại khối u, xác định tiên lượng và đánh giá đáp ứng điều trị. Nó cũng tạo điều kiện cho việc lập kế hoạch điều trị phẫu thuật và không phẫu thuật21, đẩy nhanh quá trình khám phá thuốc22và tạo điều kiện theo dõi tái phát. Các công cụ AI có thể được tích hợp vào các thử nghiệm lâm sàng, nhằm cải thiện kết quả của bệnh nhân và có thể cung cấp con đường hướng tới liệu pháp cá nhân hóa15,23. Trong hình ảnh thần kinh lâm sàng, AI đóng một vai trò quan trọng trong các nhiệm vụ như xác định ranh giới và loại khối u, tinh chỉnh kế hoạch tiền trị liệu và đánh giá phản ứng sau điều trị24. Khả năng AI xử lý các bộ dữ liệu mở rộng cung cấp một cách tiếp cận biến đổi đối với y học chính xác, có khả năng giải quyết các điểm đau thường gặp ở tất cả các bước của trải nghiệm chăm sóc bệnh nhân25,26,27 (Hình. 1). Ngoài ra, nó hứa hẹn trong việc cải thiện sự chênh lệch chăm sóc sức khỏe toàn cầu bằng cách cung cấp quyền truy cập dân chủ vào các chiến lược chẩn đoán, tiên lượng và điều trị28,29.
Gần đây, đã có sự khám phá ngày càng tăng về việc tích hợp các công cụ AI vào quy trình làm việc X quang và bệnh lý, cho thấy những tiến bộ tiềm năng trong ung thư thần kinh30,31. Trong phân tích khối u não, AI đóng vai trò là một khuôn khổ toàn diện bao gồm các kỹ thuật học máy (ML) và học sâu (DL), thị giác máy tính (CV) và tích hợp chúng vào Sinh học tính toán. Các thuật toán ML trong AI góp phần nhận dạng mẫu trong dữ liệu hình ảnh và gen, trong khi DL, một tập hợp con của ML, vượt trội trong việc trích xuất tính năng phức tạp. Thị giác máy tính, cho dù thông qua các kỹ thuật xử lý hình ảnh cổ điển hay phương pháp DL tiên tiến, diễn giải dữ liệu hình ảnh để phân tích hình ảnh y tế chính xác. Sinh học tính toán tận dụng AI, ML và DL để phân tích các bộ dữ liệu sinh học mở rộng, giúp hiểu các khía cạnh di truyền và phân tử của khối u não (Bảng bổ sung 1). Sức mạnh tổng hợp giữa các kỹ thuật này giúp tăng cường độ sâu và độ chính xác của đặc tính khối u não, ảnh hưởng đến chẩn đoán, tiên lượng và lập kế hoạch điều trị.
Khi tiến hành đánh giá này, một tìm kiếm tài liệu toàn diện đã được thực hiện trên một số cơ sở dữ liệu điện tử. Việc tìm kiếm tập trung vào các bài báo được xuất bản gần đây, tập trung vào các nghiên cứu liên quan đến các ứng dụng AI trong chẩn đoán, tiên lượng và điều trị chính xác khối u não. Chiến lược tìm kiếm của chúng tôi ưu tiên các bài viết được đánh giá ngang hàng, đánh giá có hệ thống, phân tích tổng hợp và nghiên cứu mang tính bước ngoặt trong lĩnh vực này. Đánh giá tường thuật này cung cấp một sự hiểu biết toàn diện về vai trò quan trọng của AI trong việc quản lý các khối u não ác tính nguyên phát, tập trung vào u thần kinh đệm. Nó khám phá các ứng dụng AI trong chẩn đoán khối u não, tiên lượng, lập kế hoạch điều trị và phân tích dự đoán. Giải quyết bản chất nhiều mặt của AI trong ung thư thần kinh, chúng tôi thảo luận về các dấu ấn sinh học, ý nghĩa đạo đức, phương pháp sáng tạo và thách thức, bao gồm cả những cân nhắc về sự khác biệt cụ thể về chủng tộc và giới tính trong các ứng dụng AI và nỗ lực giải quyết sự chênh lệch trong giới hạn công việc hiện tại. Điều làm cho đánh giá của chúng tôi khác biệt là tập trung rõ ràng vào việc tích hợp AI trong X quang, bệnh lý và bộ gen để phân tích khối u não toàn diện. Không giống như các bài báo trước, đánh giá của chúng tôi nhấn mạnh sự hội tụ của các ứng dụng AI trên X quang, bệnh lý và bộ gen, cung cấp một cách tiếp cận toàn diện để chẩn đoán, tiên lượng và lập kế hoạch điều trị khối u não. Mặc dù nhiều đánh giá trước đây đã thảo luận rộng rãi về AI trong ung thư thần kinh, nhưng chúng thường thiếu sự nhấn mạnh cụ thể về sự tích hợp hiệp đồng của AI trên các lĩnh vực quan trọng này. Tập trung vào việc lập kế hoạch chẩn đoán, tiên lượng và điều trị trong lĩnh vực hình ảnh, bài báo của chúng tôi không chỉ khám phá những tiến bộ mới nhất trong AI phù hợp với bệnh lý, X quang và bộ gen mà còn giải quyết những khoảng trống do các đánh giá trước đó để lại trong việc hiểu đầy đủ vai trò liên kết của các ngành này trong quản lý khối u não. Cách tiếp cận tập trung này đóng góp một quan điểm độc đáo, nêu chi tiết vai trò biến đổi của AI trong việc tinh chỉnh các chẩn đoán, tiên lượng và lập kế hoạch điều trị dựa trên hình ảnh, vốn không được bao phủ kỹ lưỡng bởi các đánh giá rộng hơn, ít chuyên môn hơn trong lĩnh vực này.
Các loại dữ liệu và bộ dữ liệu để phân tích khối u não
Phân tích khối u não dựa trên một loạt các loại dữ liệu được sử dụng hiệu quả bởi các thuật toán AI để tiết lộ các đặc điểm quan trọng. Các danh mục dữ liệu chính bao gồm dữ liệu hình ảnh, dữ liệu gen và dữ liệu lâm sàng. Các kỹ thuật hình ảnh y tế, chẳng hạn như MRI và CT, cung cấp cơ hội để trích xuất các đặc điểm thị giác phức tạp về kích thước, vị trí, hình thái và kết cấu khối u. Tiêu chuẩn hiện tại cho hình ảnh khối u não liên quan đến MRI đa tham số, bao gồm các trình tự như trọng số T1 trước và sau tương phản, trọng số T2, phục hồi đảo ngược giảm chất lỏng (FLAIR), trọng số khuếch tán (DWI) và hình ảnh trọng số nhạy cảm (SWI) như các trình tự thường thu được. Các trung tâm ung thư thần kinh khối lượng lớn thường kết hợp các kỹ thuật bổ sung như quang phổ MR và hình ảnh tưới máu11,32. Ngoài hình ảnh tiêu chuẩn, radiomics trích xuất các đặc điểm định lượng, trong khi dữ liệu mô bệnh học, có nguồn gốc từ sinh thiết hoặc phẫu thuật cắt bỏ, bao gồm hình thái tế bào khối u và kiến trúc mô. Dữ liệu gen, bắt nguồn từ trình tự DNA và RNA, phân tích phiên mã và phân tích methyl hóa, hỗ trợ phân loại các phân nhóm và dự đoán sự xâm lấn của khối u33. Hơn nữa, các dấu ấn sinh học phân tử nổi bật đóng một vai trò quan trọng trong việc phân biệt giữa các phân nhóm khối u não1,9,34. Chúng bao gồm đột biến IDH đối với u tế bào hình sao và u oligodendrogliomas, đột biến chất kích thích TERT đối với u nguyên bào thần kinh đệm, khuếch đại EGFR đối với u nguyên bào thần kinh đệm, tăng nhiễm sắc thể 7 và mất nhiễm sắc thể 10 đối với u nguyên bào thần kinh đệm, đột biến ATRX đối với u tế bào hình sao, methyl hóa chất kích thích MGMT đối với u nguyên bào thần kinh đệm, đồng xóa nhiễm sắc thể 1p và 19q đối với u oligodendroglia và các phân nhóm phân tử riêng biệt cho u nguyên bào tủy (MB)9 (Xem Bảng 2 và 3). Cuối cùng, Dữ liệu lâm sàng, bao gồm lịch sử bệnh nhân, hồ sơ y tế và đáp ứng điều trị, góp phần vào hồ sơ chẩn đoán toàn diện, với dữ liệu kết quả đóng vai trò là tài liệu tham khảo quan trọng cho các mô hình dự đoán tỷ lệ sống sót (xem Bảng 1).
Bảng 1: Tổng quan về các loại dữ liệu trong phân tích khối u não
Ngoài các loại dữ liệu được sử dụng tiêu chuẩn hơn, các phương pháp sáng tạo như sinh thiết lỏng đã xuất hiện để phát hiện sớm các khối u não35. Phân tích DNA khối u tuần hoàn (ctDNA), một phương pháp không xâm lấn, theo dõi đột biến khối u và thay đổi di truyền thông qua các đoạn DNA khối u trong máu36,37. Việc tích hợp các loại dữ liệu đa dạng và công nghệ tiên tiến này cho phép một kỷ nguyên mới của các phương pháp tiếp cận chính xác, xâm lấn tối thiểu và hiệu quả để chẩn đoán và điều trị khối u não, khắc phục những hạn chế của các phương pháp chẩn đoán thông thường. Việc tích hợp nhiều nguồn dữ liệu thông qua hợp nhất dữ liệu đa phương thức giúp tăng cường độ chính xác của các phân tích bằng cách cung cấp cái nhìn toàn diện hơn về đặc điểm và hành vi của khối u38(Hình. 2). Tổng quan ngắn gọn về từng loại dữ liệu, bao gồm mô tả và mục đích của nó, được cung cấp trong Bảng 1.
Hình 2: Tích hợp đa phương thức để tăng cường chẩn đoán, tiên lượng và dự đoán đáp ứng điều trị trong các khối u não.
Hiển thị là khung cấu trúc của một phương pháp tích hợp đa phương thức được thiết kế để cải thiện quản lý khối u não. Quá trình này liên quan đến việc đồng hóa dữ liệu từ năm nguồn khác nhau, mỗi nguồn đóng góp thông tin duy nhất. Từ quét MRI, dữ liệu phóng xạ được tạo ra. Dữ liệu này bao gồm các hình ảnh MRI được phân đoạn đạt được thông qua các kỹ thuật phân đoạn do AI điều khiển, cung cấp thông tin về các đặc điểm không gian của khối u. Các mẫu máu mang lại ctDNA, cho phép trích xuất các thay đổi biểu sinh, phân mảnh và bộ gen thông báo cho cảnh quan phân tử của khối u. Các mẫu CFS cung cấp DNA không có tế bào (cfDNA), cung cấp thông tin thay đổi bộ gen và góp phần hiểu biết toàn diện về hồ sơ di truyền của khối u. Các mẫu mô nhúng parafin (FFPE) cố định chính thức cung cấp dữ liệu bệnh lý phiên mã và phân tử, cung cấp thông tin về biểu hiện gen và cấu trúc tế bào. Thông tin lâm sàng như tuổi, chủng tộc, giới tính và dữ liệu hồ sơ y tế điện tử (EMR) bổ sung cho dữ liệu phân tử và hình ảnh, làm phong phú thêm hồ sơ của bệnh nhân. Đối với mỗi phương thức này, việc trích xuất tính năng được thực hiện, tạo ra một tập hợp các đặc điểm thông tin. Sau đó, các mô hình dự đoán được áp dụng cho từng bộ dữ liệu để ước tính các kết quả chính liên quan đến chẩn đoán, tiên lượng và đáp ứng điều trị. Trong quá trình tích hợp đa phương thức muộn, các dự đoán từ các mô hình riêng biệt này được hợp nhất để cải thiện hiệu suất và độ chính xác. Bằng cách tổng hợp thông tin từ nhiều nguồn và phương thức khác nhau, phương pháp tích hợp giúp tăng cường độ tin cậy và độ chính xác của chẩn đoán ung thư thần kinh, tiên lượng và dự đoán đáp ứng điều trị (Được tạo bằng BioRender.com).
Ngoài các bộ dữ liệu thể chế, nhiều bộ dữ liệu công khai đóng một vai trò quan trọng trong việc đánh giá các thuật toán dựa trên AI để chẩn đoán, tiên lượng và lập kế hoạch điều trị khối u não. Phù hợp với nhu cầu nghiên cứu đa dạng, các bộ dữ liệu này bao gồm các khía cạnh khác nhau của bệnh. Lưu trữ hình ảnh ung thư (TCIA) đáng chú ý trong số các bộ dữ liệu khối u não nói chung, cung cấp một kho lưu trữ toàn diện dữ liệu hình ảnh y tế, bao gồm quét MRI, CT và PET cho các loại khối u khác nhau39. MICCAI BraTS Challenge cung cấp các bộ dữ liệu phân đoạn khối u não được tiêu chuẩn hóa hàng năm, lý tưởng để đánh giá các thuật toán tập trung vào phân định khối u chính xác40.
Đối với các loại khối u cụ thể, các tài nguyên như bộ dữ liệu NCI TARGET bao gồm các phần dành riêng cho u nguyên bào thần kinh đệm (TCGA-GBM) và u thần kinh đệm cấp thấp hơn (TCGA-LGG)41. Các nền tảng bổ sung như liên minh dữ liệu mở và chung dữ liệu NCI cung cấp các bộ dữ liệu truy cập mở trên các lĩnh vực khoa học, bao gồm các bộ dữ liệu y tế và khối u não42,43. Việc lựa chọn bộ dữ liệu phù hợp nhất phụ thuộc vào các yếu tố như loại khối u, phương thức hình ảnh, loại dữ liệu (MRI, CT, PET, v.v.), tính khả dụng của chú thích sự thật cơ bản và kích thước dữ liệu, cho phép các nhà nghiên cứu điều chỉnh lựa chọn của họ với các lợi ích nghiên cứu cụ thể cho các cuộc điều tra dựa trên AI về chẩn đoán khối u não và lập kế hoạch điều trị.
Những tiến bộ trong tiền xử lý tăng cường AI để phân tích khối u não chính xác
Trong phân tích khối u não, AI đã giải quyết những thách thức trong việc điều hướng giải phẫu não và sự biến đổi khối u và tăng cường đáng kể các bước tiền xử lý quan trọng để chẩn đoán, tiên lượng và lập kế hoạch điều trị chính xác. Giải quyết các vấn đề về tính nhất quán không gian, các thuật toán được hỗ trợ bởi AI, chẳng hạn như các thuật toán được tích hợp vào trình xem BrainNet, sửa các tạo tác và biến dạng trong hình ảnh MRI44. Sự điều chỉnh này tạo điều kiện cho việc định vị và phân đoạn khối u chính xác hơn, điều này rất quan trọng để phân tích khối u não hiệu quả.
Hơn nữa, AI hợp lý hóa quá trình nội địa hóa khối u phức tạp với độ chính xác vượt trội, như được chứng minh bằng các thuật toán được đánh giá trên bộ dữ liệu BraTS40. Đáng chú ý, một số phương pháp được hỗ trợ bởi AI đã đạt được độ chính xác cao trong việc khoanh vùng các khối u, do đó nâng cao hiệu quả cho các bác sĩ X quang và giảm khả năng xảy ra lỗi của con người45,46. Phân đoạn hình ảnh thông qua CNN, vốn rất giỏi trong việc khám phá các mẫu phức tạp từ dữ liệu, đã nổi lên như một công cụ mạnh mẽ47,48,49,50,51. Các thuật toán do AI điều khiển, bao gồm thuật toán nnU-Net52, thể hiện sự thành thạo đặc biệt trong việc tự động hóa nhiệm vụ quan trọng là phân đoạn các mô bình thường trong hình ảnh y tế. Phân đoạn này rất quan trọng để phân tích khối u, hỗ trợ các bác sĩ X quang xác định các khu vực cần tránh trong quá trình xạ trị hoặc phẫu thuật52. Trong những phát triển gần đây, khung học tập liên kết đã chứng minh kết quả tương đương hoặc vượt trội trong việc phân đoạn tự động các khối u trẻ em hiếm gặp từ hình ảnh MRI. Cách tiếp cận này thúc đẩy dữ liệu từ các tổ chức đa dạng trong khi vẫn đảm bảo tính bảo mật tối đa của thông tin bệnh nhân24.
Việc tích hợp dữ liệu đa phương thức giúp nâng cao hiệu quả phát hiện bằng cách khai thác các nguồn thông tin đa dạng53. Cảnh quan của DL giới thiệu các kiến trúc sáng tạo, với một số ví dụ đáng chú ý, bao gồm cả U-Net 3D46, DeepMedic54và V-Net55. 3D U-Net, được thiết kế để vượt trội trong việc phân đoạn hình ảnh 3D của u nguyên bào thần kinh đệm và được công nhận về đào tạo đơn giản và hiệu quả nhất quán, đạt được kết quả đáng chú ý trong phân đoạn khối u não. DeepMedic54, được biết đến với sự mạnh mẽ trong việc quản lý tiếng ồn và hiện vật, là đối thủ cạnh tranh mạnh mẽ với U-Net 3D, được đào tạo về hình ảnh u thần kinh đệm. V-Net, một sự đổi mới non trẻ được thiết kế để phân đoạn chính xác hình ảnh y tế thể tích, thiết lập sức mạnh của nó trong việc phân đoạn cả hình ảnh MRI 2D và 3D55. Nhìn chung, vai trò của AI trong các bước tiền xử lý này cho phép các bác sĩ X quang tiến hành phân tích khối u não với độ chính xác và hiệu quả cao.
AI trong chẩn đoán khối u não
Chẩn đoán khối u não liên quan đến việc xác định và mô tả đặc điểm của sự tăng trưởng hoặc khối lượng bất thường trong não, sử dụng các phương pháp hình ảnh y tế, bệnh lý và lâm sàng khác nhau để xác định bản chất, vị trí và đặc điểm của khối u55. Các khối u não khác nhau dựa trên nguồn gốc, vị trí, mô học, bệnh ác tính và tuổi của bệnh nhân, và phân loại chúng là rất quan trọng để chẩn đoán, tiên lượng và lập kế hoạch điều trị55. Những khối u này bao gồm các phân nhóm đa dạng, mỗi loại được đặc trưng bởi nguồn gốc tế bào và đặc điểm mô học riêng biệt. Trong khi u thần kinh đệm và MB loại thấp và cao cấp ở trẻ em thường gặp nhất ở trẻ em, u nguyên bào thần kinh đệm, u thần kinh đệm lan tỏa và u màng não chiếm ưu thế ở người lớn56. Do tầm quan trọng của chúng, trọng tâm chủ yếu của nghiên cứu là u nguyên bào thần kinh đệm và u thần kinh đệm lan tỏa khác ở người lớn và MB, và u thần kinh đệm cấp thấp và cao cấp ở trẻ em57,58. Xác định chính xác phân nhóm khối u cho phép các bác sĩ lâm sàng tùy chỉnh các phương pháp chẩn đoán, dự đoán hành vi bệnh và thông báo các liệu pháp nhắm mục tiêu59. Chữ ký di truyền và mô học độc đáo liên quan đến các loại khối u khác nhau cung cấp thông tin về tính tích cực và đáp ứng điều trị, hướng dẫn lựa chọn phương thức hình ảnh, đánh giá dấu ấn sinh học và kế hoạch điều trị60.
Các khối u não thường được xác định trên CT được thực hiện trong môi trường phòng cấp cứu, trước khi được đặc trưng thêm thông qua MRI và được chẩn đoán dứt khoát thông qua kiểm tra mô bệnh học56. Tiêu chuẩn chăm sóc trong bệnh học thần kinh hiện nay bao gồm xét nghiệm phân tử và di truyền cho nhiều loại khối u, được hướng dẫn bởi các phát hiện mô học ban đầu57. Các phương pháp chẩn đoán hiện tại phải đối mặt với những thách thức58,59,60 chẳng hạn như phát hiện sớm do che giấu khối u61, giới hạn hình ảnh20, và các vấn đề về hình dung các khối u nhỏ hoặc sâu62,63, khó khăn trong việc phân biệt các loại khối u64, thủ thuật xâm lấn với các rủi ro liên quan65, và sự không đồng nhất của khối u não66. Những cách tiếp cận này bị cản trở bởi các quy trình tốn thời gian, khả năng tiếp cận hạn chế và sự thay đổi giải thích giữa các chuyên gia, làm nổi bật sự cần thiết của các phương pháp dựa trên AI tiên tiến16,67.
AI có thể gia tăng giá trị ở tất cả các bước chẩn đoán khối u, với phần lớn các nghiên cứu hiện tại cố gắng tạo ra các mô hình dự đoán được đào tạo bằng cách sử dụng dữ liệu hình ảnh, dữ liệu bệnh lý hoặc cả hai chế độ dữ liệu kết hợp68. Việc tích hợp các mô hình AI trong chẩn đoán khối u não cho thấy tiềm năng, đặc biệt là trong việc phân biệt giữa u thần kinh đệm và di căn não đơn độc bằng các phương pháp phân tích hình ảnh định lượng69,70. Hình ảnh thần kinh cung cấp một cái nhìn độc đáo về toàn bộ khối u không thay đổi, trong khi các phân tích bệnh lý cung cấp một cái nhìn sâu hơn về các đặc điểm tế bào và phân tử của khối u. ML, như một yếu tố quan trọng của AI, đang góp phần vào những tiến bộ trong chẩn đoán khối u não bằng cách tăng cường độ chính xác, đẩy nhanh phân tích hình ảnh, cho phép phát hiện sớm và cải thiện sự khác biệt giữa các loại khối u. Tiến bộ gần đây trong CV, ML và DL có tiềm năng giải quyết các thách thức và cải thiện chăm sóc bệnh nhân trong chẩn đoán khối u não45.
X quang được hỗ trợ bởi AI và các phương pháp chẩn đoán dựa trên mô học
Chẩn đoán khối u não dựa trên X quang và mô học liên quan đến việc trích xuất các đặc điểm định lượng từ hình ảnh y tế như quét MRI hoặc H &E WHI để nắm bắt hình thái, kết cấu và mối quan hệ không gian của khối u. Các phương pháp trích xuất tính năng truyền thống như phân tích kết cấu (Ma trận đồng xuất hiện cấp độ xám (GLCM), Ma trận độ dài chạy cấp độ xám (GLRLM) và Haralick71,72), Phân tích hình dạng73, Phân tích cường độ74, Phân tích dựa trên Wavelet75, được bổ sung bởi các cách tiếp cận mới hơn. Sau đó, ML và DL xây dựng các mô hình dự đoán, cho phép cách tiếp cận chẩn đoán dựa trên dữ liệu, được cá nhân hóa31,76,77. Các kỹ thuật phổ biến bao gồm CNN, RNN, máy biến áp tầm nhìn, mạng đối nghịch sinh sản (GAN)78, hỗ trợ máy vector và rừng ngẫu nhiên77 (Bảng bổ sung 1). Các mô hình được tạo ra từ nhiều chuỗi, chẳng hạn như mpMRI đã được chứng minh là chính xác hơn khi so sánh với các mô hình trình tự đơn79 để phát hiện khối u, đánh giá cấp độ và hướng dẫn lập kế hoạch điều trị80.
Các phương pháp chẩn đoán dựa trên mô học, được liên kết bởi cuốn sách phân loại CNS năm 2021 của WHO (Tổ chức Y tế Thế giới), là trung tâm của bệnh lý khối u não. Phân tích dựa trên mô học bao gồm các kỹ thuật phân tử khác nhau tận dụng dữ liệu mô học để tăng cường chẩn đoán khối u não. Methylome profiling, một kỹ thuật có ảnh hưởng gần đây sử dụng phân loại dựa trên AI / ML, đã trở thành một kỹ thuật có ảnh hưởng để phân loại và chẩn đoán khối u não81. Mặc dù phân loại năm 2021 của WHO hỗ trợ việc sử dụng các bộ phân loại methylome cho các khối u não khác nhau như là tiêu chí thiết yếu hoặc mong muốn, nhưng vẫn có cuộc tranh luận đang diễn ra về phương pháp tốt nhất và khả năng tiếp cận hạn chế của các xét nghiệm chẩn đoán34. U thần kinh đệm sâu82, một hệ thống sàng lọc chẩn đoán dựa trên AI, cung cấp kết quả nhanh chóng (<90 giây) bằng cách hợp lý hóa chẩn đoán phân tử GMG bằng cách sử dụng hình ảnh mô học Raman (SRH) được kích thích. Hệ thống sáng tạo này đã được phát triển và xác nhận trên một đoàn hệ đa trung tâm, làm nổi bật tiềm năng của nó để chẩn đoán khối u não nhanh chóng và chính xác82.
Hơn nữa, các phương pháp tiếp cận sáng tạo sử dụng phóng xạ trên quét tưới máu MRI đã chứng minh khả năng dự đoán đột biến IDH, cung cấp thông tin có giá trị cho chẩn đoán và lập kế hoạch điều trị83. Quang phổ Terahertz đã được khám phá như một kỹ thuật không xâm lấn để dự đoán đột biến IDH trong các mẫu mô u thần kinh đệm, trình bày một giải pháp thay thế đầy hứa hẹn cho các phương pháp hiện có84. Hơn nữa, các kỹ thuật phân tích tiên tiến được áp dụng cho quét PET / CT 18F-FET đã cho phép dự đoán cả cấp độ u thần kinh đệm và tình trạng đột biến IDH ở những bệnh nhân không được điều trị85. Đáng chú ý, một chữ ký hình ảnh học sâu (DLIS) đã được phát triển, đưa ra dự đoán chính xác về sự đồng xóa 1p / 19q trong u thần kinh đệm mức độ thấp lan tỏa thông qua quét MRI trước phẫu thuật, đưa ra một giải pháp thay thế không xâm lấn với tiềm năng chẩn đoán đáng kể86.
Sự tích hợp của hóa mô miễn dịch, hồ sơ methyl hóa, vi mảng nhiễm sắc thể, scRNA-seq87và NGS, với phân tích dựa trên mô học có thể tăng cường hơn nữa chẩn đoán khối u não81,88. Trong khi các phương pháp tiếp cận thông thường, sử dụng hình ảnh, sinh thiết mô và xét nghiệm di truyền, tự tin xác định nhiều khối u não bằng cách kết hợp mô học với những thay đổi di truyền cụ thể, vẫn tồn tại các trường hợp ngoại lệ, chẳng hạn như u sao bào cao cấp với các đặc điểm piloid, được giới thiệu trong phân loại năm 2021 của WHO88,89. Tình trạng đặc biệt này đòi hỏi hồ sơ methylome để chẩn đoán89, nhưng sự hiếm gặp của nó cho thấy rằng phân loại methylome phù hợp nhất cho các trường hợp cụ thể với các biểu hiện lâm sàng và bệnh lý không điển hình. Một phương pháp học sâu gần đây có tên là “Cá tầm”, có thể phân loại nhanh chóng và chính xác các loại khối u thần kinh trung ương trong quá trình phẫu thuật bằng cách sử dụng dữ liệu mảng methyl hóa thưa thớt thu được từ trình tự nanopore được tạo ra trong quá trình phẫu thuật. Nó phân loại các khối u thần kinh trung ương trong vòng 40 phút sau khi bắt đầu giải trình tự, với độ chính xác 72% trong cài đặt phẫu thuật thời gian thực90. Phương pháp này cho phép các bác sĩ phẫu thuật đưa ra quyết định sáng suốt hơn về mức độ cắt bỏ, có khả năng làm giảm nguy cơ biến chứng và cải thiện kết quả của bệnh nhân.
AI trong tiên lượng khối u não
Tiên lượng trong ung thư thần kinh liên quan đến việc ước tính tiến triển bệnh cho một cá nhân, xem xét kế hoạch điều trị, giai đoạn bệnh và vị trí91. Các chỉ số chính là tỷ lệ sống sót tổng thể (HĐH) và tỷ lệ sống không tiến triển (PFS), rất quan trọng để đánh giá tiên lượng và hướng dẫn điều trị92. Tuy nhiên, các phương pháp thông thường dựa vào giai đoạn bệnh và các biến lâm sàng phải đối mặt với những hạn chế, bao gồm sự phức tạp về diễn giải, thành kiến và sự cần thiết của các bộ dữ liệu mở rộng. Đạt được độ chính xác cho chăm sóc cá nhân trong việc dự đoán tái phát và tỷ lệ sống sót vẫn còn thách thức với các phương pháp thông thường.
Trong chăm sóc khối u não, AI đóng một vai trò quan trọng trong việc thúc đẩy khả năng tiên lượng. Các kỹ thuật ML và DL đang ngày càng được khai thác để dự đoán hệ điều hành và PFS, tận dụng các tính năng được trích xuất từ dữ liệu hình ảnh trước khi xử lý. Các nghiên cứu đáng chú ý, bao gồm chữ ký phóng xạ từ quét T1 và FLAIR MRI của bệnh nhân u nguyên bào thần kinh đệm69và quét T1, T2 và FLAIR từ những bệnh nhân chưa điều trị, cho thấy hứa hẹn đáng kể trong việc dự đoán PFS và HĐH93,94. Các mô hình AI hoạt động tốt hơn các biến lâm sàng thông thường và chứng minh sự xuất sắc khi kết hợp với các thuộc tính lâm sàng ở bệnh nhân u nguyên bào thần kinh đệm95,96. Đáng chú ý, các mô hình dựa trên MRI trọng số T297 và các đặc điểm phóng xạ từ phù quanh khối u cho thấy mối liên quan với kết quả sống sót, vị trí tái phát và phân nhóm phân tử98, đặc biệt là trong u thần kinh đệm97và bệnh nhân u nguyên bào thần kinh đệm99. Các mô hình dựa trên DL được tạo ra để xác định các khối u và dự báo vị trí tái phát, đôi khi trước khi các bác sĩ X quang có thể phát hiện ra nó100. Những mô hình này, sử dụng các phương pháp hình ảnh khác nhau, làm nổi bật khả năng dự đoán đặc biệt của AI97,99 (Bảng 2).
Bảng 2 Các mô hình tiên lượng dựa trên AI trong nghiên cứu khối u não: đoàn hệ bệnh nhân và chiến lược trích xuất tính năng
Hơn nữa, sự không đồng nhất trong khối u và độ dẻo của trạng thái tế bào đã được xác định là động lực chính cho tình trạng kháng trị liệu của u nguyên bào thần kinh đệm30. Hồ sơ phiên mã không gian và tiên lượng từ hình ảnh mô học đã được dự đoán bằng cách sử dụng khung DL này, làm sáng tỏ tiềm năng của AI trong việc làm sáng tỏ các khía cạnh phức tạp của hành vi khối u30. Ngoài ra, việc xác định đột biến IDH đã được tận dụng để hướng dẫn tiên lượng, trong khi định nghĩa về u nguyên bào thần kinh đệm đã được tinh chỉnh thông qua phân tích chất xúc tiến TERT, khuếch đại EGFR, tăng nhiễm sắc thể 7 và mất nhiễm sắc thể 10. Ngoài ra, H3F3A đã nổi lên như một dấu hiệu quan trọng cho các khối u trẻ em xâm lấn101.
AI trong quản lý điều trị khối u não
Ngoài việc tăng thêm giá trị cho cả khả năng chẩn đoán và tiên lượng, AI đã được sử dụng để cải thiện kế hoạch điều trị khối u não và đánh giá đáp ứng điều trị102. Nó biến đổi các phương pháp điều trị và tăng cường độ chính xác bằng cách hỗ trợ xác định và mô tả đặc điểm của các khối u não. Nó hướng dẫn các bác sĩ lâm sàng trong việc xác định các chiến lược điều trị phù hợp nhất cho từng bệnh nhân. Quá trình nhiều mặt này bao gồm các kỹ thuật đa dạng, bao gồm hình ảnh, đánh giá lâm sàng, sinh thiết và phân tích phân tử, để xác định chính xác sự hiện diện, loại, vị trí và mức độ của khối u.
Các phương pháp dựa trên AI vượt trội trong việc dự đoán đáp ứng trị liệu, cho phép cải thiện kế hoạch điều trị trên các bệnh ung thư khác nhau103. Các phương pháp tiếp cận mới, chẳng hạn như dự đoán phản ứng với xạ phẫu bằng dao gamma đối với các khối u não di căn bằng cách sử dụng các tính năng phóng xạ104 từ quét T1 và FLASH tăng cường độ tương phản và sử dụng các mô hình dự đoán dựa trên bản đồ ADC tiền điều trị để dự báo đáp ứng với xạ trị, cho thấy hiệu quả của AI104. Các mô hình tích hợp, kết hợp phóng xạ với các thuộc tính lâm sàng, đánh giá hiệu quả đáp ứng xạ trị cho bệnh nhân di căn não do ung thư vú và ung thư phổi nguyên phát trên các nhóm bệnh nhân đa trung tâm105. Phân tích không đồng nhất không gian của phù quanh khối u (ED) trong u nguyên bào thần kinh đệm hỗ trợ xác định môi trường sống có nguy cơ cao trong ED, dẫn đến tăng cường lập kế hoạch điều trị106. Trong khi việc xác định dấu hiệu quan trọng MGMT cho tình trạng kháng temozolomide (TMZ) ở bệnh nhân u nguyên bào thần kinh đệm đưa ra những thách thức, các phương pháp phóng xạ dựa trên AI nổi lên như là yếu tố dự đoán về cả tình trạng MGMT và phản ứng TMZ, cung cấp những hiểu biết có giá trị cho các quyết định điều trị sáng suốt101.107 (Bảng 3).
Bảng 3 Quản lý điều trị khối u não tăng cường AI: hiểu biết sâu sắc từ các nghiên cứu và phương thức điều trị
Trong các phương pháp tiếp cận đa phương thức và đa quy mô, hy vọng là sự hiểu biết toàn diện hơn về các khối u não thông qua việc tích hợp bộ gen, bệnh lý và dữ liệu phóng xạ. Bộ gen, đặc biệt là thông qua các kỹ thuật như NGS, đóng một vai trò nổi bật trong việc làm sáng tỏ cảnh quan di truyền của các khối u não, cung cấp thông tin về sự thay đổi bộ gen của chúng88. Phân nhóm phân tử và dấu ấn sinh học được xác định đóng một vai trò quan trọng trong y học chính xác cá nhân hóa, tác động đến việc phát hiện sớm, tiên lượng và dự đoán đáp ứng điều trị. Cách tiếp cận tích hợp này, khi kết hợp với dữ liệu lâm sàng, nâng cao sự hiểu biết của chúng tôi và đặt nền tảng cho các phương pháp điều trị phù hợp nhắm vào các thay đổi di truyền cụ thể.
Bổ sung cho nền tảng gen này, các kỹ thuật hình ảnh đa phương thức như MRI, CT và PET đóng góp một lớp phong phú cho tấm thảm tích hợp, mặc dù có những thách thức về chi phí và thời gian108. Khi kết hợp với chuyên môn lâm sàng và các dữ liệu chẩn đoán khác, hình ảnh đa mô thức giúp tăng cường đáng kể độ chính xác chẩn đoán. Sự tích hợp của bộ gen và phóng xạ, được tạo điều kiện bởi AI, nổi lên như một lực lượng cách mạng trong việc hiểu và điều trị các khối u não.
Hơn nữa, những tiến bộ của AI vượt ra ngoài các dự đoán đơn phương, mở ra một kỷ nguyên của các phương pháp tiên lượng và điều trị đa phương thức. Các phương pháp tiếp cận đa phương thức, đa phương thức này trích xuất các tính năng từ các nguồn dữ liệu đa dạng, bao gồm hình ảnh phóng xạ và hình ảnh đa phương thức, dẫn đến sự hiểu biết toàn diện và chính xác hơn về quỹ đạo bệnh100 (Hình. 2).
Những thách thức và hạn chế của AI trong chẩn đoán, tiên lượng và điều trị khối u não
Mặc dù tích hợp thành công các mô hình AI trong các bước khác nhau của quản lý khối u não, những thách thức vẫn tồn tại. Những thách thức này bao gồm quyền truy cập hạn chế vào dữ liệu chất lượng cao, mối quan tâm về khả năng diễn giải và khả năng giải thích của các mô hình DL và nhu cầu khái quát hóa trên các quần thể và loại khối u khác nhau109. Khả năng tái tạo của các đặc điểm dựa trên phóng xạ trên các viện khác nhau phải đối mặt với những thách thức do sự thay đổi trong các thông số thu nhận hình ảnh, bao gồm máy móc, mô hình và lượng tương phản110. Đặc biệt, việc đạt được khả năng tái tạo phức tạp hơn trong bức xạ MR so với bức xạ CT111. Để chuẩn hóa phóng xạ, việc giới thiệu điểm chất lượng phóng xạ (RQS) là rất quan trọng112. Tuy nhiên, bất chấp tầm quan trọng của việc xác nhận phương pháp AI trong ung thư thần kinh bằng cách sử dụng bộ dữ liệu bên ngoài, chỉ có 29,4% nghiên cứu ban đầu bao gồm xác nhận bên ngoài113.
Ngoài ra, trong quản lý khối u não, rõ ràng là sự chênh lệch chủng tộc tạo ra các động lực phức tạp được định hình bởi chủng tộc, các biến số kinh tế xã hội và ảnh hưởng địa lý114. Sự phức tạp này mở rộng đến nhiều khía cạnh khác nhau, bao gồm các khuyến nghị cho phẫu thuật khối u não115, nhấn mạnh tầm quan trọng của việc giải quyết sự chênh lệch như vậy trong các phương pháp dựa trên AI trong toàn bộ phổ quản lý khối u não để thúc đẩy chăm sóc ung thư. Hơn nữa, sự chênh lệch về tỷ lệ và kết quả khối u não, đặc biệt là trong u nguyên bào thần kinh đệm, biểu hiện khác nhau giữa nam và nữ116. Điều này nhấn mạnh sự cần thiết của các phương pháp tiếp cận dựa trên AI đối với các yếu tố ảnh hưởng liên quan đến giới tính về tỷ lệ mắc, tỷ lệ sống, sinh học khối u, di truyền, đáp ứng điều trị và tiên lượng. Ưu điểm chính của các mô hình này nằm ở việc đưa ra các dự đoán nâng cao để điều trị cá nhân hóa và tiềm năng phát hiện sớm bằng cách tính đến các đặc điểm giới tính cụ thể.
Ý nghĩa đạo đức, pháp lý và xã hội của AI trong quản lý khối u não
Việc tích hợp AI trong chẩn đoán, tiên lượng và điều trị khối u não làm tăng các cân nhắc quan trọng về đạo đức, pháp lý và xã hội117. Các mối quan tâm đạo đức chính bao gồm đảm bảo quyền riêng tư của bệnh nhân thông qua các biện pháp bảo mật dữ liệu mạnh mẽ, có được sự đồng ý có hiểu biết, giải quyết sự công bằng thuật toán và thúc đẩy tính minh bạch trong các thuật toán AI và trách nhiệm giải trình để xây dựng và duy trì niềm tin của bệnh nhân28. Những đổi mới như học tập liên kết nhằm giải quyết thách thức về quyền riêng tư trong AI bằng cách cho phép đào tạo mô hình hợp tác giữa nhiều bên mà không cần chia sẻ dữ liệu thô24. Các mệnh lệnh đạo đức mở rộng để giải quyết các thành kiến và đảm bảo tiếp cận công bằng. Các cân nhắc pháp lý, bao gồm trách nhiệm pháp lý đối với các lỗi do AI tạo ra, các tiêu chuẩn sơ suất y tế và tuân thủ quy định, nhấn mạnh sự cần thiết phải có các khung pháp lý mạnh mẽ. Các nỗ lực hợp tác liên quan đến các nhà hoạch định chính sách, cơ quan quản lý và chuyên gia pháp lý là rất quan trọng để làm rõ trách nhiệm, bảo vệ sự an toàn của bệnh nhân và thúc đẩy phát triển AI có trách nhiệm. Ý nghĩa xã hội, chẳng hạn như tác động đến mối quan hệ giữa bệnh nhân và bác sĩ, trao quyền cho bệnh nhân và chênh lệch về chăm sóc sức khỏe, đòi hỏi phải xem xét cẩn thận. AI có tiềm năng trao quyền cho bệnh nhân bằng cách cung cấp thông tin được cá nhân hóa và cho phép ra quyết định chung117.118. Tuy nhiên, khả năng tiếp cận công bằng và khả năng chi trả của chăm sóc sức khỏe do AI điều khiển cần được giải quyết để tránh làm trầm trọng thêm sự chênh lệch hiện có117.118.
Sự thảo luận
Đánh giá này nhấn mạnh tác động biến đổi của AI trong quản lý khối u não, biểu thị sự thay đổi mô hình trong chăm sóc sức khỏe nhằm giải quyết những thách thức lâu dài. Sự thành thạo của AI trong các kỹ thuật ML và DL, đặc biệt là trong phân đoạn hình ảnh, tính nhất quán không gian và dự đoán, giúp tăng cường độ chính xác trong việc xác định và mô tả các khối u não. Độ chính xác này góp phần cải thiện chẩn đoán, tiên lượng và lập kế hoạch điều trị cá nhân hóa. Sự tích hợp liền mạch của các loại dữ liệu đa dạng, từ hình ảnh y tế đến bộ gen, cùng với lịch sử lâm sàng, cho phép hiểu toàn diện về đặc điểm khối u, định hình tiên lượng và kế hoạch điều trị cá nhân hóa. Tiềm năng của AI trong việc trao quyền cho các bác sĩ lâm sàng theo dõi thời gian thực, lập kế hoạch điều trị nâng cao và tối ưu hóa được nhấn mạnh, hứa hẹn cải thiện kết quả của bệnh nhân.
Khả năng tiên lượng của các mô hình dựa trên AI vượt qua các biến lâm sàng thông thường, cung cấp độ chính xác dự đoán vượt trội và tinh chỉnh dự đoán tỷ lệ sống sót30. Việc tích hợp AI trong việc dự đoán đáp ứng điều trị, thời gian sống sót và vị trí tái phát là một tiến bộ đáng kể, cho phép các liệu pháp chính xác, được cá nhân hóa phù hợp với đặc điểm khối u riêng lẻ và dữ liệu cụ thể của bệnh nhân. Chẩn đoán dựa trên AI không chỉ tạo điều kiện theo dõi thời gian thực mà còn cải thiện việc lập kế hoạch và tối ưu hóa điều trị. Phần này nhấn mạnh tiềm năng của AI trong việc cung cấp các can thiệp chính xác, cá nhân hóa và hiệu quả hơn, góp phần nâng cao kết quả của bệnh nhân. Các hệ thống hỗ trợ quyết định lâm sàng, được trao quyền bởi AI, không chỉ cung cấp các khuyến nghị điều trị dựa trên bằng chứng mà còn đóng góp vào nghiên cứu đang diễn ra bằng cách tạo ra những hiểu biết và dấu ấn sinh học mới.
Những cân nhắc về đạo đức trong việc tích hợp AI trong chẩn đoán, tiên lượng và điều trị khối u não được thừa nhận, bao gồm quyền riêng tư dữ liệu, công bằng thuật toán, trách nhiệm pháp lý và ý nghĩa xã hội. Các khung pháp lý mạnh mẽ và các nỗ lực hợp tác như học tập liên kết được coi là cần thiết để giải quyết những thách thức này đối với sự phát triển AI có trách nhiệm và sự chấp nhận của xã hội trong chăm sóc sức khỏe. Bất chấp những thách thức như chi phí thu thập dữ liệu và sự phức tạp trong diễn giải, tích hợp AI hứa hẹn đáng kể, mang lại triển vọng chăm sóc bệnh nhân chính xác và được cá nhân hóa trong tương lai. Tuy nhiên, thay đổi lực lượng lao động và đào tạo có thể cần thiết để tích hợp hiệu quả các công nghệ AI vào các cơ sở chăm sóc sức khỏe. Sự chấp nhận đạo đức và xã hội của AI trong chăm sóc sức khỏe phụ thuộc vào giao tiếp minh bạch, giải quyết các mối quan tâm về quyền riêng tư và thúc đẩy các hoạt động công bằng và toàn diện.
Nhìn chung, AI mở rộng ảnh hưởng của nó vào việc lập kế hoạch điều trị, cách mạng hóa các chiến lược điều trị và góp phần đáng kể vào việc cải thiện kết quả của bệnh nhân. Việc tích hợp AI vào bối cảnh điều trị hứa hẹn cho các can thiệp được cá nhân hóa và hiệu quả trong ung thư thần kinh.
Một tầm nhìn cho tương lai: một loạt các phương pháp tiếp cận
Việc tích hợp AI trong chẩn đoán, điều trị và tiên lượng khối u não đã có những tiến bộ đáng kể, nhưng vẫn còn những khoảng trống và hướng đi đầy hứa hẹn trong tương lai để khám phá. Tích hợp dữ liệu đa phương thức108, các chiến lược theo dõi, chẩn đoán và điều trị thích ứng theo thời gian thực có tiềm năng nâng cao độ chính xác chẩn đoán và kết quả điều trị90. AI có thể đóng một vai trò quan trọng trong việc tiên lượng dài hạn và lập kế hoạch chăm sóc sống sót, hỗ trợ việc ra quyết định điều trị. Thu hẹp khoảng cách giữa thực hành lâm sàng và nghiên cứu thông qua các mạng chia sẻ dữ liệu có thể đẩy nhanh quá trình phát triển và xác nhận mô hình AI. Tính minh bạch và khả năng giải thích của các mô hình AI là điều cần thiết để đạt được sự tin tưởng và chấp nhận trong môi trường lâm sàng119.120. Các cân nhắc về đạo đức và các nguyên tắc thiết kế lấy con người làm trung tâm phải được ưu tiên để đảm bảo tích hợp AI có trách nhiệm và lấy bệnh nhân làm trung tâm. Bằng cách giải quyết các khía cạnh này, AI có tiềm năng cách mạng hóa việc chăm sóc khối u não và cải thiện kết quả của bệnh nhân120.
Hình dung tương lai của phân tích khối u não, DL đứng ở vị trí hàng đầu, nhưng các kỹ thuật khác nhau vẫy gọi khám phá dựa trên các ứng dụng cụ thể và tính sẵn có của dữ liệu. Cải thiện các phương pháp hình ảnh, chẳng hạn như chụp cộng hưởng từ chức năng (fMRI)121 và hình ảnh tensor khuếch tán (DTI)122, cung cấp đặc điểm khối u chính xác hơn, bất chấp những thách thức như nhạy cảm với tiếng ồn, chuyển động đầu, biến dạng từ trường và chi phí tính toán123.124. Những tiến bộ tính toán, đặc biệt là CNN và các mô hình dựa trên Transformer, tăng cường độ chính xác trong việc phát hiện và phân loại các khối u não125.126.127. Hợp nhất dữ liệu đa phương thức108, bao gồm chụp MRI, CT và PET38, cùng với việc chuyển giao học tập bằng cách sử dụng các mô hình được đào tạo trước từ các bộ dữ liệu hình ảnh rộng lớn, giải quyết thách thức của dữ liệu y tế được gắn nhãn hạn chế77 (Bảng bổ sung 1).
Các phương pháp dựa trên đồ thị thúc đẩy các mối quan hệ vùng não phức tạp128, với mạng nơ-ron đồ thị (GNN) và mạng tích chập dựa trên đồ thị (GCN) chiếu sáng con đường mô hình hóa kết nối não và phát hiện ra những bất thường liên quan đến khối u129. Radiomics và kỹ thuật tính năng trích xuất một loạt các tính năng định lượng từ hình ảnh y tế, với các thuật toán ML chiếu sáng các mẫu và mối tương quan. AI có thể giải thích (XAI), một khía cạnh quan trọng, đảm bảo tính minh bạch và khả năng diễn giải thuật toán, một nền tảng trong các ứng dụng y tế130.131. Những nỗ lực gần đây đã hướng tới việc tạo ra các mô hình AI với đầu ra có thể giải thích được, thúc đẩy sự hiểu biết của các bác sĩ lâm sàng về các quy trình ra quyết định và do đó nuôi dưỡng niềm tin vào việc phát hiện và phân loại khối u não tự động. Các kỹ thuật tăng cường và tổng hợp dữ liệu, bao gồm xoay hình ảnh, chia tỷ lệ, lật và sự khéo léo của GAN, củng cố tính mạnh mẽ của tập dữ liệu đào tạo78.127. Ngoài ra, AutoML và các công cụ tối ưu hóa siêu tham số hợp lý hóa việc tối ưu hóa kiến trúc và siêu tham số trong các thuật toán phát hiện khối u não, đỉnh cao là các mô hình hiệu quả và chính xác hơn.
Các nền tảng và bộ dữ liệu cộng tác, chẳng hạn như học tập liên kết24.132Các kho lưu trữ dữ liệu khối u não được chú thích tỉ mỉ, đẩy nhanh quá trình đào tạo, đánh giá và đổi mới thuật toán đồng thời xúc tác cho các nỗ lực đo điểm chuẩn. Lĩnh vực phát hiện thời gian thực, được thúc đẩy bởi những tiến bộ trong phần cứng như bộ xử lý đồ họa (GPU) và mảng cổng lập trình trường (FPGA), mở ra tiềm năng xử lý hình ảnh y tế theo thời gian thực90.133. Các thuật toán thời gian thực như vậy hứa hẹn hợp lý hóa quy trình làm việc lâm sàng và nâng cao chăm sóc bệnh nhân. Việc sử dụng gần đây các Mô hình ngôn ngữ lớn (LLM) trong nghiên cứu thần kinh thể hiện khả năng đáng chú ý để phân tích các nguồn dữ liệu đa dạng, đóng góp đáng kể cho chẩn đoán sớm, hỗ trợ bệnh nhân và hỗ trợ lâm sàng. Những thách thức đáng chú ý, bao gồm các mối quan tâm liên quan đến quyền riêng tư và thành kiến dữ liệu, nhấn mạnh sự bắt buộc đối với các nỗ lực hợp tác để đảm bảo sự phát triển có trách nhiệm của LLM trong thần kinh học134 (Bảng bổ sung 1).
Kết luận
Chúng tôi đã khám phá các ứng dụng biến đổi của AI, bao gồm CV, ML và DL, trong việc quản lý các khối u não. AI cho thấy hứa hẹn đáng kể trong chẩn đoán, tiên lượng và lập kế hoạch điều trị bằng cách phát hiện và phân loại hiệu quả các khối u não từ hình ảnh y tế. Thông qua các phân tích phóng xạ, bệnh lý và bộ gen, AI góp phần mô tả chính xác đặc điểm khối u. Trong điều trị, AI đóng một vai trò quan trọng trong việc lập kế hoạch, tối ưu hóa và dự đoán phản hồi, hỗ trợ các đề xuất được cá nhân hóa và giám sát thời gian thực. Việc tích hợp các phương pháp tiếp cận dựa trên AI phù hợp với y học chính xác và chăm sóc lấy bệnh nhân làm trung tâm. Tuy nhiên, việc áp dụng AI trong quản lý khối u não đòi hỏi phải xem xét cẩn thận các tác động đạo đức, pháp lý và xã hội, giải quyết các mối quan tâm liên quan đến quyền riêng tư dữ liệu và chênh lệch chăm sóc sức khỏe.
Các định hướng trong tương lai bao gồm thu hẹp khoảng cách nghiên cứu, khám phá các mô hình LLM, tích hợp dữ liệu đa phương thức và thúc đẩy giám sát thời gian thực. Các mô hình AI được đào tạo trên các bộ dữ liệu đa dạng hứa hẹn sẽ dự đoán đáp ứng điều trị và cải thiện kết quả của bệnh nhân. Sự phát triển và tinh chỉnh liên tục là điều cần thiết để khám phá toàn bộ tiềm năng và thách thức trong quản lý lâm sàng các khối u não, định vị AI như một công cụ có giá trị trong nghiên cứu và thực hành.
Họ nói rằng đó là điều ‘phải xem’ nếu bạn ở Lisbon nên tất nhiên tôi đã đến xem.
Tháp Belem.
Được xây dựng từ năm 1514-1520, trong thời kỳ đỉnh cao của thời kỳ Phục hưng Bồ Đào Nha, Tháp Belém đôi khi được gọi là Tháp St Vincent vì công trình xây dựng này nhằm kỷ niệm chuyến thám hiểm tới Ấn Độ của Vasco da Gama, nhà thám hiểm nổi tiếng người Bồ Đào Nha.Nó được coi là một trong những ví dụ điển hình nhất về kiến trúc thời bấy giờ, được gọi là phong cách Manuelino, nhưng nó cũng bao gồm các đặc điểm Moorish đặc biệt như tháp pháo được trang trí công phu.
Tháp đóng vai trò là điểm chuyển tiếp của các nhà thám hiểm Bồ Đào Nha và là cửa ngõ nghi lễ đến Lisbon, cũng như được sử dụng để bảo vệ thành phố vào thời đó.Từ năm 1983, Tháp Belem đã được UNESCO công nhận là Di sản Thế giới.Thật không may, trong chuyến đi này, nó đã bị đóng cửa đối với du khách nhưng với tư cách là một nhiếp ảnh gia ‘ngoài trời’, tôi không bận tâm đến điều đó.