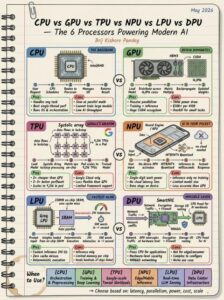
Vai trò và chuyên môn của bộ xử lý
Các kiến trúc chính được định nghĩa
-
CPU (Bộ xử lý trung tâm): Hoạt động như “bộ não” của bất kỳ máy tính nào, thực hiện các tác vụ tuần tự và quản lý hệ điều hành thông qua các lõi tốc độ cao và hệ thống bộ nhớ đệm lớn. Mặc dù rất cần thiết cho các ứng dụng đòi hỏi nhiều quyết định, nhưng nó lại kém hiệu quả hơn trong các phép toán ma trận lớn, lặp đi lặp lại cần thiết cho các mô hình AI hiện đại.
-
GPU (Bộ xử lý đồ họa): Ban đầu được thiết kế để hiển thị hình ảnh, cấu trúc song song cao của nó khiến nó trở thành công cụ chủ lực để huấn luyện và chạy các mô hình AI nhờ khả năng thực hiện hàng nghìn phép toán đồng thời.
-
TPU (Tensor Processing Unit): Một ASIC (Application-Specific Integrated Circuit) chuyên dụng được Google phát triển, được thiết kế đặc biệt để tăng tốc các phép toán tensor, mang lại hiệu quả vượt trội cho việc huấn luyện các mô hình transformer quy mô lớn trong môi trường điện toán đám mây.
-
NPU (Bộ xử lý thần kinh): Được tối ưu hóa cho suy luận AI tiết kiệm năng lượng, NPU ngày càng được tích hợp trực tiếp vào các thiết bị tiêu dùng (như điện thoại thông minh và máy tính xách tay) để xử lý các tác vụ nền như nhận dạng giọng nói và xử lý hình ảnh mà không làm hao pin của hệ thống chính.
-
LPU (Bộ xử lý ngôn ngữ): Được xây dựng để giảm thiểu độ trễ trong suy luận LLM (Mô hình ngôn ngữ lớn), LPU vượt trội trong việc tạo ra các từ ngữ tuần tự, từng từ một, cần thiết cho trí tuệ nhân tạo đàm thoại thời gian thực, thường vượt qua GPU trong các bài kiểm tra thời gian tạo ra từ ngữ đầu tiên.
-
DPU (Bộ xử lý dữ liệu): Tập trung vào hiệu quả của trung tâm dữ liệu, DPU hoạt động như một “người bảo vệ mạng”, giảm tải các tác vụ cơ sở hạ tầng như mã hóa, bảo mật tường lửa và di chuyển dữ liệu khỏi CPU, cho phép bộ xử lý chính tập trung hoàn toàn vào logic ứng dụng.
Brij kishore Pandey
Hầu hết mọi người chỉ biết đến 2 trong số 6 bộ xử lý này.
Đó là một điểm mù nguy hiểm trong năm 2026.
Khi ai đó nói “chạy khối lượng công việc AI này” — việc lựa chọn bộ xử lý sẽ quyết định bạn chi 300 đô la hay 30.000 đô la, chờ 10 giây hay 10 mili giây, và liệu dữ liệu có bao giờ rời khỏi thiết bị hay không.
Đây là sơ đồ đầy đủ:
CPU — Xương sống
→ Đa năng. Tuần tự. Điều phối.
→ Mọi quy trình AI đều bắt đầu và kết thúc ở đây
→ Không phải anh hùng — mà là người điều khiển
Tốt nhất cho: Tiền xử lý, định tuyến, quản lý I/O
GPU — Con ngựa chiến
→ 16.896 lõi CUDA chạy song song
→ Lý do tồn tại của các LLM hiện đại
→ Hơn 30.000 đô la mỗi H100, công suất tiêu thụ 700W — không hề nhỏ
Tốt nhất cho: Huấn luyện + suy luận ở quy mô lớn
TPU — Vũ khí bí mật của Google
→ Kiến trúc mảng song song — dữ liệu chảy đồng bộ
→ Rẻ hơn GPU gấp 2 lần, hiệu suất/watt tốt hơn 2-3 lần
→ 9.216 TPU trong một cụm duy nhất
Tốt nhất cho: Khối lượng công việc tensor quy mô Google
NPU — AI trong túi của bạn
→ Suy luận trên thiết bị. Không cần đám mây. Không độ trễ. → Lượng tử hóa INT8/INT4. Công suất tiêu thụ chỉ vài watt.
→ Thời gian phản hồi 5ms. Dữ liệu không bao giờ rời khỏi thiết bị.
Tốt nhất cho: Suy luận trên thiết bị biên và thiết bị di động
LPU — Quái thú tốc độ
→ 230MB SRAM tích hợp trên chip. Không lỗi bộ nhớ cache.
→ 241 token/giây. Luôn luôn chính xác.
→ Tạo ra 500 từ trong vòng chưa đầy 1 giây
Tốt nhất cho: Phục vụ LLM thời gian thực
DPU — Lớp Vô Hình
→ SmartNIC chặn lưu lượng truy cập ở cấp độ phần cứng
→ Xử lý mã hóa, tường lửa, I/O lưu trữ
→ Giải phóng hoàn toàn CPU cho các tác vụ AI
Tốt nhất cho: Cơ sở hạ tầng trung tâm dữ liệu
Các yếu tố cần cân nhắc:
→ Độ trễ là quan trọng nhất? → LPU hay NPU
→ Huấn luyện mô hình? → GPU hay TPU
→ Mở rộng quy mô lớn trên Google Cloud? → TPU
→ Lưu trữ dữ liệu trên thiết bị? → NPU
→ Bảo mật lưu lượng trung tâm dữ liệu? → DPU
→ Mọi thứ khác? → CPU vẫn đang điều khiển mọi thứ
Điều quan trọng cần hiểu: các hệ thống AI hiện đại không chỉ sử dụng một bộ xử lý.
Chúng sử dụng cả sáu bộ xử lý — mỗi bộ thực hiện chính xác chức năng được thiết kế của nó.
GPU huấn luyện mô hình.
TPU mở rộng quy mô.
NPU phục vụ nó trên điện thoại của bạn.
LPU trả lời trong vòng chưa đầy một giây.
DPU bảo mật cơ sở hạ tầng bên dưới.
CPU kết nối tất cả lại với nhau.
Hiểu toàn bộ hệ thống là điều phân biệt các kỹ sư AI với người dùng AI.
Bạn thực sự đang làm việc với thành phần nào trong số 6 thành phần này hàng ngày — và bạn nghĩ thành phần nào đang bị các kỹ sư đánh giá thấp nhất hiện nay?
Cấu hình công nghệ:
Máy tính Dell trang bị card đồ họa NVIDIA RTX PRO 5000 Blackwell (24GB GDDR7)
#DellProMax #DellTech #NVIDIA #DellProPrecision
(St.)

Ý kiến bạn đọc (0)