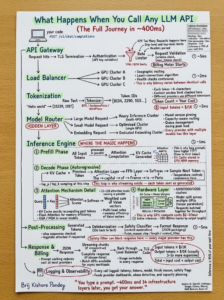
Khi bạn gọi bất kỳ API LLM nào, lời nhắc văn bản của bạn sẽ được gửi qua internet đến một máy chủ từ xa, nơi nó được xử lý bởi một mô hình ngôn ngữ quy mô lớn và phản hồi có cấu trúc được trả về, thường là ở dạng JSON.
Dòng chảy cấp cao
-
Yêu cầu đi đến cổng API – Yêu cầu HTTP của bạn chạm vào biên của nhà cung cấp (ví dụ: ), trong đó TLS bị chấm dứt, khóa API của bạn được xác thực và giới hạn tốc độ được kiểm tra.
https://api.openai.com/... -
Định tuyến và cân bằng tải – Cổng định tuyến yêu cầu đến một cụm GPU phù hợp, thường là trung tâm dữ liệu gần nhất với dung lượng khả dụng và có thể xếp hàng dưới tải nặng.
-
Tokenization – Văn bản đầu vào của bạn được chia thành các mã thông báo (biểu diễn số) bằng thuật toán như BPE hoặc SentencePiece; Hệ thống cũng kiểm tra xem bạn có vượt quá giới hạn khung thời gian ngữ cảnh hoặc tốc độ ở đây hay không.
Suy luận mô hình
-
Lựa chọn mô hình và phân lô – Một bộ định tuyến mô hình chọn đúng cụm (mô hình nhỏ so với mô hình lớn, nhúng so với trò chuyện) và thường gửi hàng loạt yêu cầu của bạn với những người khác để giữ cho GPU bận rộn.
-
Giai đoạn điền trước – Tất cả các mã thông báo đầu vào được xử lý trong một lần; tính toán chú ý xây dựng bộ nhớ đệm khóa-giá trị (KV) trong bộ nhớ GPU, đó là lý do tại sao lời nhắc dài làm tăng độ trễ và chi phí.
-
Giai đoạn giải mã (tạo) – Mã thông báo được tạo từng cái một bằng cách sử dụng ngữ cảnh được lưu trong bộ nhớ cache; Lấy mẫu (nhiệt độ, ) được áp dụng để chọn từng mã thông báo tiếp theo và nếu bật tính năng phát trực tuyến, đầu ra sẽ được gửi dần dần.
top_p
Sau mô hình
-
Xử lý hậu kỳ – ID mã thông báo đầu ra được chuyển đổi trở lại văn bản, bộ lọc an toàn có thể xem xét nội dung và mọi trình tự hoặc ràng buộc khác đều được thực thi.
stop -
Thanh toán và phản hồi – Hệ thống ghi lại số lượng mã thông báo đầu vào và đầu ra, áp dụng giá và gửi phản hồi JSON trở lại khách hàng của bạn với siêu dữ liệu sử dụng và văn bản được tạo.
Nói tóm lại, từ quan điểm mã của bạn, đó là một lệnh gọi HTTP đơn giản, nhưng đằng sau hậu trường, nó kích hoạt một quy trình phức tạp gồm mạng, mã hóa, suy luận GPU phân tán và các lớp thanh toán an toàn mọi lúc.
(St.)

Ý kiến bạn đọc (0)